ОПГС - Основы построения гиперконвергентных систем
- Лабораторные работы
- Лабораторная работа 0. Изучение работы текстового редактора VIM.
- Лабораторная работа 1. Работа с консолью в Linux.
- Лабораторная работа 2. Работа с дисковой подсистемой ОС Linux.
- Лабораторная работа 3. Работа с сетью в Linux. Виртуальный коммутатор Linux Bridge.
- Лабораторная работа 4. Основы виртуализации в Linux. QEMU/KVM.
- Лабораторная работа 5. Основы виртуализации в Linux. Libvirt.
- Лабораторная работа 6. Основы виртуализации в Linux. Отказоустойчивый кластер на базе Corosync/Pacemaker.
- Лабораторная работа 7. Основы виртуализации в Linux. Динамическая миграция ресурсов в отказоустойчивом кластере на базе Corosync/Pacemaker.
- Практические задания
- Практическое задание №1. Создание виртуальной машины в новом проекте
- Практическое задание №3.Создание сервиса облачного хранилища
- Практическое задание №4.Wireguard
- Практическое задание №5-1. Запуск кластера Ceph
- Практическое задание №5-2. Установка клиентской ВМ и настройка динамической миграции на базе Corosync/Pacemaker
- Практическое задание №5-3. Ceph FS, Ceph Dashboard
Лабораторные работы
Лабораторная работа 0. Изучение работы текстового редактора VIM.
Цель
Получение базовых навыков при работе с основным текстовым редактором операционной
системе Linux (CentOS 7).
Задачи
- Подключиться к облачной платформе
- Установить пакет vim
- Пройти обучение работе с vim.
Схема виртуального стенда

Для работы с облачной платформой необходимо прочитать инструкцию.
Переключиться на проект [GROUP]:[team]-lab:1-2.
Подключиться к labnode, логин - labuser, пароль - labpass1!
Задание 1. Подключиться к облачной платформе.
Для работы с облачной платформой необходимо прочитать инструкцию.
Задание 2. Установить пакет vim
Для установки, удаления, обновления пакетов в ОС CentOS 7 используется утилита yum (аббр.
Yellowdog Updater, Modified).
В процессе установки/обновления/удаления пакетов нужно будет подтвердить установку новых
версий, нажав y. Или же использовать флаг -y.
Необходимо установить пакет vim, в котором содержится необходимое обучающее руководство.
sudo yum install vim
Задание 3. Пройти обучение работе с vim.
Ввести в консоли следующую команду, для запуска интерактивного обучающего курса по работе с VIM:
vimtutor ru
Пройти интерактивный курс до конца.
Лабораторная работа 1. Работа с консолью в Linux.
Цель
Получение базовых навыков при работе с консолью в операционной системе Linux (CentOS 7).
Задачи
- Подключиться к виртуальной машине в RESDS Dashboard.
- Выполнить базовые действия с файлами и папками.
- Установить пакет wget.
- Научиться работать с переменными окружения.
- Создать нового пользователя и подключиться к нему. Поменять shell у пользователя.
- Изучить работу с текстом в Bash.
Схема виртуального стенда

Для работы с облачной платформой необходимо прочитать инструкцию.
Переключиться на проект [GROUP]:[team]-lab:1-2.
Подключиться к labnode, логин - labuser, пароль - labpass1!
Задание 1. Работа с файловой системой.
- Создать директорию task01. Перейти в неё.
mkdir task01
cd task01
- Создать в домашнем каталоге текстовый файл user при помощи текстового редактора
vi, и заполнить его произвольными символами.
vi user
- Скопировать файл
userв новый файл с именемroot.
cp user root
- Посмотреть права доступа на файлы можно с помощью команды:
ls -l
- Задать владельца root и группу root на файл root. (sudo позволяет выполнять команды от
root; ввести пароль в диалоговом окне, при этом символы отображаться не будут; пароль -labpass1!)
sudo chown root:root root
- Переименовать (т.е. переместить с новым именем) файл
userв файлlock.
mv user lock
- На файл root поставить доступ на чтение и запись группе и владельцу остальным только на чтение.
sudo chmod 664 root
- На файл lock поставить доступ на чтение владельцу, группе и остальным пользователям убрать доступ на чтение запись и исполнение.
chmod 600 lock
- Вывести содержимое файла root в терминал.
cat root
- Отредактировать файл root случайным образом и вывести его содержимое в консоль.
sudo vi root
cat root
- Удалить каталог task01.
cd
sudo rm -rf task01
Задание 2. Установка пакетов.
Для установки, удаления, обновления пакетов в ОС CentOS 7 используется утилита yum (аббр. Yellowdog Updater, Modified).
В процессе установки/обновления/удаления пакетов нужно будет подтвердить установку новых версий, нажав y. Или же использовать флаг -y.
Для установки/удаления пакетов существуют команды:
sudo yum install -y package_name
sudo yum remove -y package_name
В качестве примера необходимо установить программу для скачивания файлов по web-протоколам - wget.
sudo yum install wget
Можно проверить версию установленного пакета:
wget –-version
Задание 3. Создание пользователей.
Создать нового пользователя newuser с паролем newpass1!. Сделать его администратором.
sudo adduser newuser
sudo passwd newuser # Ввести пароль newpass1!, при этом пароль отображаться не будет
sudo usermod -aG wheel newuser # Добавить пользователя newuser в группу wheel, что даст ему права на исполнение команд с sudo
Для того, чтобы выполнять команды от имени пользователя newuser, необходимо сменить текущее окружение на окружение пользователя newuser командой - su. При этом нужно будет ввести пароль пользователя newuser.
su - newuser
Имя пользователя изменилось с labuser на newuser. Также, имя пользователя хранится в переменной окружения $USER. Просмотреть значение переменной можно с помощью команды echo.
echo $USER
Чтобы узнать, в каких группах состоит текущий пользователь, используется команда groups. В данном случае это должны быть группы newuser и wheel.
groups
Для выхода из оболочки используется команда exit. При этом выход идет в оболочку, запущенную пользователем labuser.
exit
Теперь нужно сменить оболочку, запускаемую по умолчанию при входе пользователя newuser. Чтобы узнать список доступных в системе оболочек, используется следующая команда:
cat /etc/shells
Сейчас должна быть запущена оболочка /bin/bash. Чтобы узнать, какая оболочка запущена сейчас, можно вывести на экран значение переменной $0.
echo $0
Чтобы просто запустить оболочку, достаточно просто набрать путь к ней. Запустить оболочку - sh, и вывести на экран переменную - $0. После выйти обратно в bash.
/bin/sh
echo $0
exit
Чтобы сменить оболочку по умолчанию для пользователя, можно отредактировать файл /etc/passwd, либо можно использовать утилиту usermod. Необходимо посмотреть, какая оболочка сейчас является оболочкой по умолчанию для пользователя newuser, сменить её на /bin/sh, и проверить изменения.
sudo grep newuser /etc/passwd # grep - программа для поиска по тексту. В данном случае, выведет все строки, содержащие newuser.
sudo usermod --shell /bin/sh newuser
sudo grep newuser /etc/passwd # Данная команда произведет поиск по файлу
# /etc/passwd, и отобразит в консоли все
# строки, в которых присутствует слово
# newuser. В этой же строке будет указано,
# какая оболочка используется данным
# пользователем
Теперь необходимо переключиться в режим работы от имени пользователя newuser, и проверить, какая оболочка используется. После выйти из этого режима, и удалить пользователя.
su - newuser
echo $0
exit
sudo userdel -r newuser # флаг r используется, когда вы хотите удалить также домашний каталог пользователя.
Задание 4. Работа с текстом в bash.
Для практики нужно воспользоваться текстовым файлом, специально созданным для выполнения задания - таблица подключений OpenVPN, состоящая из имени клиента, IP адреса, MAC адреса устройства и внешнего IP, с которого клиент подключился. Необходимо загрузить файл, воспользовавшись специальной утилитой s3cmd, загружающего файлы с облачного хранилища, работающему по специальному протоколу s3(simple storage server):
sudo yum install s3cmd -y
sudo yum upgrade -y
cd ~
cp /var/lib/cloud/s3cfg .s3cfg
s3cmd get s3://lab1/clients.txt ~/
Вывести содержимое файла в консоль (Тут для удобства можно пользоваться встроенными в консоль горячими клавишами: Ctrl+L - Очистить содержимое консоли, Shift+PgUp - Прокрутить консоль вверх, Shift+PgDn - Прокрутить консоль вниз).
cat ~/clients.txt
Для того, чтобы вывести строки, содержащие подстроку, можно использовать grep. Необходимо вывести информацию о клиенте под номером 24 (grep - регистрозависимый, Client24 начинается с заглавной буквы).
grep Client24 ~/clients.txt
В результате исполнения команды должна быть выведена одна строка. Если было несколько строк, содержащих подстроку Client24, то в результате выведется несколько строк. Далее необходимо ввести команду:
grep Client2 ~/clients.txt
Необходимо попробовать понять, сколько будет выведено строк и почему именно они.
Помимо обычных строк grep поддерживает также регулярные выражения. При этом регулярные выражения должны экранироваться символом . С помощью регулярных выражений можно задать абсолютно любой паттерн. Относительно простой - вывести всех клиентов, имя которых заканчивается на 4. Точка в выражении означает любой символ.
grep Client\.4 ~/clients.txt
grep также умеет работать с пайплайном (вертикальная черта). С помощью пайплайна можно передавать вывод от одной программы другой, по принципу конвейера. Например, можно вывести текст через cat, и передать этот вывод на вход команды grep, для его обработки этой командой.
cat ~/clients.txt | grep Client\.4
Пайплайнов может быть несколько. Так, например, воспользовавшись программой AWK можно вывести только имя клиента и его внешний адрес - то есть первый и четвертый столбцы. (Внимание на пробел в двойных кавычках между номерами столбцов. Это разделитель, который будет между столбцами в конечном результате. Пробел можно заменить на любой другой символ, например, на дефис -, или символ табуляции \t. Можно попробовать это сделать)
cat ~/clients.txt | grep Client\.4 | awk ‘{print $1” “$4}’
AWK также поддерживает функции в своем синтаксисе. Например, чтобы вывести имя клиента и MAC, при этом чтобы MAC печатался заглавными буквами, нужно использовать следующую конструкцию.
cat ~/clients.txt | grep Client\.4 | awk ‘{print $1” “toupper($3)}’
Далее необходимо вывести MAC адрес, чтобы он был разделён не двоеточиями, а дефисами, тогда можно воспользоваться sed. Нужно лишь задать параметры для замены. После этого результат можно вывести не в консоль, а в новый файл (набирать в одну строку):
cat ~/clients.txt | grep Client\.4 | awk ‘{print $1” “toupper($3)}’ | sed -r ‘s/:/-/g’ > newfile.txt
Лабораторная работа 2. Работа с дисковой подсистемой ОС Linux.
Цель:
Получение базовых навыков при работе с дисковой подсистемой в операционной системе Linux (CentOS 7).
Задачи
- Разметить диск как DOS (MBR), создать на его разделах файловую систему.
- Удалить разметку с диска.
- Разметить диск как GPT.
- Используя LVM создать физический том, группу томов и поверх них логические тома. Провести настройку этих томов.
- Научиться работать с файловой системой на логическом томе, с её созданием и монтированием.
- Использовать fstab для автоматизации монтирования при загрузке.
Схема виртуального стенда

Задание 1. Создание разделов с использованием fdisk на MBR.
Подключиться к labnode1, логин - labuser, пароль - labpass1!
Необходимо сделать на диске следующую разметку:

Для этого запустить fdisk в интерактивном режиме, в качестве аргумента передавая путь к блочному устройству.
sudo fdisk /dev/vdb
-
Создать разметку DOS (MBR), с помощью команды
o. -
Создать primary раздел. Нажать
n, для создания нового раздела. Нажатьp, указывая, что нужен именно primary. Номер раздела выбрать -1(можно ничего не выбирать, так как этот номер раздела используется по умолчанию). Утилита fdisk автоматически рассчитывает свободный сектор, с которого можно начать создание раздела. Для первого сектора первого раздела это будет сектор 2048 (можно ничего не выбирать, а просто нажатьenterтак как этот номер раздела используется по умолчанию. Для всех последующих разделовfdiskбудет сам вычислять первый незанятый сектор, и предлагать его по умолчанию). При указании последнего сектора необходимо указать+1G(утилитаfdiskавтоматически рассчитает нужное количество секторов). В итоге должен получиться primary раздел на 1 ГБ. Проверить, что раздел добавлен в таблицу разделов, с помощью командыp. -
Создать ещё один раздел на 5 ГБ, но с типом extended. Сделать всё то же самое как в пункте 2, но выбрать вместо primary, extended, набрав
e, и последний сектор указать+5Gот первого рекомендуемого. -
Создать два логических раздела по 1 ГБ и один на 2 ГБ (логические тома могут быть созданы только при наличии extended раздела, и размещаются “внутри” extended раздела). Для этого выбрать тип раздела - logical, нажав
l. -
Создать еще один primary раздел на 1 ГБ.
-
Проверить получившуюся таблицу разделов, с помощью
p. Если всё было сделано правильно, должен получиться следующий результат:
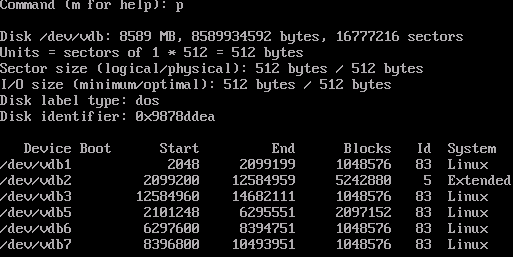
- После этого, необходимо записать эту таблицу на диск, нажав w. После выполнения этой команда утилита fdisk завершит работу и вернет вас в оболочку пользователя.
Проверить, что все изменения применились можно с помощью следующей команды:
lsblk
В результате на диске vdb должно отображаться 6 новых разделов.
Задание 2. Создание файловой системы.
Создать файловые системы на разделах, созданных в предыдущем задании. Пусть:
- На vdb1 ext4.
- На vdb3 - xfs.
- На vdb5 - btrfs.
Делается это так:
sudo mkfs.ext4 /dev/vdb1
sudo mkfs.xfs /dev/vdb3
sudo mkfs.btrfs /dev/vdb5
Проверить, что файловые системы были созданы.
sudo lsblk -f
Теперь, в каталоге пользователя, создать каталог media.
mkdir ~/media
Примонтировать раздел.
sudo mount /dev/vdb5 /home/labuser/media/
После этого можно размещать файлы в каталоге /home/labuser/media/ и они будут размещаться на диске vdb. Проверить куда и какие разделы примонтированы можно с помощью команды sudo mount без аргументов.
Для выполнения дальнейших этапов работы необходимо отмонтировать данный раздел:
sudo umount /dev/vdb5
Задание 3. Создание разделов с использованием fdisk на GPT.
Запустить fdisk в интерактивном режиме, в качестве аргумента передавая путь к блочному устройству.
sudo fdisk /dev/vdb
- Выбрать таблицу разметки GPT. Делается это, нажав
g. - Создать 3 раздела, согласно схеме. Сделать это с помощью команды
n, как и в случае с MBR.

Задание 4. Работа с LVM.
В этом задании используется разметка из задания 3. Для выполнения этого задания потребуется пакет lvm2. Установить его можно с помощью yum.
sudo yum install lvm2
Сначала необходимо изменить системный id раздела. Он влияет на то, какая метка файловой системы будет отображаться в fdisk в столбце Type.
Запустить fdisk в интерактивном режиме, в качестве аргумента передавая путь к блочному устройству.
sudo fdisk /dev/vdb
- Необходимо изменить тип раздела всем разделам. Нажав t, выбрать номер раздела, метку которого нужно поменять. Далее необходимо нажать L, чтобы просмотреть все доступные метки. Нужно найти Linux LVM (поиск в текстовой консоли может быть затруднен из-за длинного списка. Пролистать список вверх можно с помощью клавиш shift + PgUp, либо просто ввести значение метки - 31). Набрать id, под которым стоит нужная метка.
- Проделать эту операцию со всеми разделами на диске.
- Необходимо проверить введенные значения, а после записать их, нажав w.
- Необходимо сделать все три раздела физическими томами (В процессе будет сообщение, что файловая система на томе будет уничтожена. Нужно согласиться, набрав
y).
sudo pvcreate /dev/vdb1
sudo pvcreate /dev/vdb2
sudo pvcreate /dev/vdb3
Проверить успешность можно с помощью команды sudo pvdisplay. Эта команда должна вывести список всех PV(физических устройств), на которых могут быть размещены тома LVM.
- На этих физических томах создать группу томов, и задать ей имя. Имя можно выбрать любое, например vg1:
sudo vgcreate vg1 /dev/vdb1 /dev/vdb2 /dev/vdb3
Проверить с помощью sudo vgdisplay. В результате должна отобразиться 1 VG (группа томов), в данном случае vg1.
6. Теперь в группе томов можно создать логические тома lv1 и lv2 размером 1 ГБ и 2 ГБ соответственно.
sudo lvcreate -n lv1 -L 1G vg1
sudo lvcreate -n lv2 -L 2G vg1
Проверить с помощью sudo lvdisplay. В результате должны отобразиться 2 LV (логических тома) lv1 и lv2.
- Теперь в системе появились блочные устройства /dev/vg1/lv1 и /dev/vg1/lv2. Осталось создать на них файловую систему. Тут различий с обычными разделами нет.
sudo mkfs.ext4 /dev/vg1/lv1
sudo mkfs.ext4 /dev/vg1/lv2
- Удаление физических томов. Удалить из группы том /dev/vdb1. Чтобы убрать из работающей группы томов раздел, сначала необходимо перенести все данные с него на другие разделы:
sudo pvmove /dev/vdb1
Затем удалить его из группы томов:
sudo vgreduce vg1 /dev/vdb1
И, наконец, удалить физический том:
sudo pvremove /dev/vdb1
Последняя команда просто убирает отметку о том, что диск является членом lvm, и не удаляет ни данные на разделе, ни сам раздел. После удаления физического тома из LVM для дальнейшего использования диск придётся переразбивать/переформатировать.
- Добавление физических томов. Необходимо расширить VG, добавив к нему том /dev/vdb1. Чтобы добавить новый том в группу томов, создать физический том:
sudo pvcreate /dev/vdb1
Добавить его в группу:
sudo vgextend vg1 /dev/vdb1
Теперь можно создать ещё один логический диск (lvcreate) или увеличить размер существующего (lvresize).
- Изменение размеров LVM позволяет легко изменять размер логических томов. Для этого нужно сначала изменить сам логический том:
sudo lvresize -L 3G vg1/lv2
Так как логический том является обычным дисковым (блочным) устройством, расширение этого дискового устройство никак не скажется на файловой системе, находящейся на нем, и не приведет к увеличению ее размера. Чтобы файловая система заняла все свободное место на блочном устройстве, необходимо её расширить отдельной командой: А затем файловую систему на нём:
sudo resize2fs /dev/vg1/lv2
Задание 5. Монтирование разделов.
Удалить существующие логические LVM разделы, и создать новый.
sudo lvremove /dev/vg1/lv1
sudo lvremove /dev/vg1/lv2
sudo lvcreate -n media -L 6G vg1
sudo mkfs.ext4 /dev/vg1/media
Далее необходимо примонтировать раздел.
sudo mount /dev/vg1/media /home/labuser/media/
Записать тестовый файл test.
echo "string" | sudo tee ~/media/test
Если проблемы с доступом к записи, сменить владельца каталога. После выполнить команду заново.
sudo chown labuser:labuser /home/labuser/media/*
Отмонтировать раздел.
sudo umount /home/labuser/media/
Зайти внутрь созданного каталога, и удостовериться, что файла test там нет. Он остался на разделе. Чтобы после перезагрузки не монтировать раздел заново, нужно добавить автомонтирование в конфигурационный файл /etc/fstab (удалять из этого файла ничего нельзя! В случае ошибки в конфигурационном файле операционная система не загрузится, делать очень внимательно!). Для начало необходимо сохранить резервную копию конфигурационного файла:
sudo cp /etc/fstab /etc/fstab.old
Далее необходимо открыть его, чтобы изменить содержимое:
sudo vi /etc/fstab
Добавить туда следующую строку и сохранить.
/dev/vg1/media /home/labuser/media ext4 defaults 0 0
Для того, чтобы убедиться в корректности сохранения, необходимо вывести в консоль содержимое файла /etc/fstab командой:
sudo cat /etc/fstab
Необходимо проверить, что изначальное содержимое файла сохранено, и так же в нём есть добавленная запись. Если содержимое отличается от ожидаемого, то необходимо восстановить сохраненную версию, и произвести все изменения ещё раз. После этого повторить проверку. Восстановить содержимое можно следующей командой:
sudo cp /etc/fstab.old /etc/fstab
Перезагрузить систему с помощью команды reboot. После загрузки зайти в каталог ~/media, требуется увидеть файл test.
Лабораторная работа 3. Работа с сетью в Linux. Виртуальный коммутатор Linux Bridge.
Цель
Получить представления о работе сетевой подсистемы в операционной системе Linux (CentOS
7), и научиться выполнять базовые действия с ней. Научиться работать с виртуальным
коммутатором Linux Bridge.
Задачи
- Задать статический IP адрес на интерфейс.
- Настроить объединение интерфейсов.
- Настроить сетевой мост.
- Настроить VxLAN(виртуальные сети).
- Ознакомиться с возможностями сетевых утилит.
Схема виртуального лабораторного стенда

Задание 1. Установка статического IP адреса физическому интерфейсу
Переключиться на проект [GROUP]:[team]-lab:3.
Подключиться к labnode-1. логин - labuser, пароль - labpass1!
Подключение должно быть выполнено по следующей схеме (рис. 1).

Воспользоваться утилитой ip. Для того, чтобы увидеть существующие в системе интерфейсы, набрать команду:
ip address
Там же будут отображены основные параметры этих сетевых интерфейсов.
Команда ip позволяет использовать короткие имена команд. в данном случае, вместо ip address можно использовать команду
ip a
В случае правильного выполнения команд (для всех команд кроме ip address) утилита ip не будет
возвращать никакого значения. В случае, если команда выполнена неправильно, будет
возвращена соответствующая ошибка.
Задать интерфейсу eth1 IP адрес:
sudo ip address add 10.0.12.20/24 dev eth1
Изменить состояние на up.
sudo ip link set up dev eth1
Посмотреть изменения (состояние устройства eth1 должно измениться на UP):
ip address
Подключиться к labnode-2. Установить интерфейсу eth1 IP адрес:
sudo ip address add 10.0.12.30/24 dev eth1
Изменить состояние на up:
sudo ip link set up dev eth1
С labnode-1 проверить доступность labnode-2:
ping -c 4 10.0.12.30
После перезагрузки сервера, или сервиса сети все изменения отменяются. Перезагрузить оба сервера, и посмотреть на состояние интерфейсов (необходимо проверить, сохранились ли на интерфейсе адреса, заданные предыдущими командами):
reboot
ip address
Задание 2. Настройка статического адреса через конфигурационные файлы
Подключение должно быть выполнено по следующей схеме (рис. 1). Для того, чтобы изменения оставались в силе, нужно настроить интерфейс через конфигурационный файл. Тогда настройки будут загружаться при старте системы. Создать конфигурацию интерфейса eth1 на labnode-1:
sudo vi /etc/sysconfig/network-scripts/ifcfg-eth1
И привести его к следующему виду:
TYPE=Ethernet
DEVICE=eth1
BOOTPROTO=static
IPADDR=10.0.12.20
PREFIX=24
ONBOOT=yes
Основные параметры:
- TYPE - Тип сетевого интерфейса
- NAME - Имя интерфейса
- DEVICE - Устройство, которое интерфейс использует
- BOOTPROTO - если этот параметр static, то интерфейс не будет автоматически получать адрес от сети, маску и другие параметры подключения. В случае необходимости автоматического получения адреса – необходимо указать значение этого параметра -dhcp.
- ONBOOT - включать ли интерфейс при загрузке.
- IPADDR - IP-адрес
- DNS1 - DNS, через который обращаться к доменам. Можно указать несколько параметров: DNS1, DNS2...
- PREFIX - префикс, другой способ задания маски сети. Для префикса 24 маска будет 255.255.255.0
- GATEWAY - шлюз
Все остальные параметры являются необязательными в данной лабораторной работе, и могут быть удалены.
Скопировать файл ifcfg-eth1 с именем ifcfg-eth2:
sudo cp /etc/sysconfig/network-scripts/ifcfg-eth1 /etc/sysconfig/network-scripts/ifcfg-eth2
Отредактировать его с помощью редактора vi:
sudo vi /etc/sysconfig/network-scripts/ifcfg-eth2
И привести его содержимое к следующему виду:
TYPE=Ethernet
DEVICE=eth2
BOOTPROTO=static
IPADDR=10.0.12.21
PREFIX=24
ONBOOT=yes
Перезагрузить сеть и посмотреть интерфейсы:
sudo systemctl restart network
ip address
Далее необходимо настроить интерфейсы на узле labnode-2, по такому же принципу, как и labnode-1. Создать конфигурацию интерфейса eth1:
sudo vi /etc/sysconfig/network-scripts/ifcfg-eth1
И привести его к следующему виду:
TYPE=Ethernet
DEVICE=eth1
BOOTPROTO=static
IPADDR=10.0.12.30
PREFIX=24
ONBOOT=yes
Скопировать файл ifcfg-eth1 с именем ifcfg-eth2:
sudo cp /etc/sysconfig/network-scripts/ifcfg-eth1 /etc/sysconfig/network-scripts/ifcfg-eth2
В оболочке bash (и во многих других оболочках) для упрощения ввода текста выше можно использовать упрощенную форму ввода текста выше:
sudo cp /etc/sysconfig/network-scripts/ifcfg-eth{1,2}
Отредактировать его через vi:
sudo vi /etc/sysconfig/network-scripts/ifcfg-eth2
И привести к следующему виду:
TYPE=Ethernet
DEVICE=eth2
BOOTPROTO=static
IPADDR=10.0.12.31
PREFIX=24
ONBOOT=yes
Перезагрузить сеть и посмотреть интерфейсы:
sudo systemctl restart network
ip address
Проверить доступность интерфейсов:
(labnode-1) ping -c 4 10.0.12.30
(labnode-1) ping -c 4 10.0.12.31
(labnode-2) ping -c 4 10.0.12.20
(labnode-2) ping -c 4 10.0.12.21
Задание 3. Настройка объединения интерфейсов.
"Объединение" (bonding) сетевых интерфейсов - позволяет совокупно собрать несколько портов в одну группу, эффективно объединяя пропускную способность в одном направлении. Например, вы можете объединить два порта по 100 мегабит в 200 мегабитный магистральный порт.
<I>В некоторых случаях интерфейсы после перезапуска сетевой службы не удаляют ip адреса,
что связано с особенностью работы up/down скриптов. В таком случае в системе на разных
интерфейсах может присутствовать одинаковый ip адрес (проверить можно командой ip address). Для решения этой проблемы необходимо отчистить все адреса на интерфейсе.
Сделать это можно как просто удалив конкретный адрес с интерфейса, так и
воспользоваться специальной командой, которая очистит все имеющиеся на нём адреса:
sudo ip address flush dev eth1
sudo ip address flush dev eth2
Подключение должно быть выполнено по следующей схеме (рис. 2).

Для того, чтобы создать интерфейс bond0, нужно создать файл конфигурации:
sudo vi /etc/sysconfig/network-scripts/ifcfg-bond0
Конфигурация bond0 интерфейса на labnode-1 будет следующей:
TYPE=Bond
DEVICE=bond0
BOOTPROTO=static
IPADDR=10.0.12.20
PREFIX=24
BONDING_MASTER=yes
BONDING_OPTS="mode=0 miimon=100"
ONBOOT=yes
Это создаст сам bond0 интерфейс. Но нужно также назначить физические интерфейсы eth1 и eth2, как подчиненные ему. Необходимо изменить конфигурационный файл eth1:
sudo vi /etc/sysconfig/network-scripts/ifcfg-eth1
И привести его к следующему виду:
TYPE=Ethernet
DEVICE=eth1
MASTER=bond0
SLAVE=yes
То же самое сделать и с eth2:
sudo vi /etc/sysconfig/network-scripts/ifcfg-eth2
TYPE=Ethernet
DEVICE=eth2
MASTER=bond0
SLAVE=yes
Перезагрузить сеть.
sudo systemctl restart network
Посмотреть, что получилось:
ip address
В полученном выводе интерфейсы eth1 и eth2 должны быть в подчиненном режиме (SLAVE), а интерфейс bond0 должен иметь ip адрес и находиться в состоянии UP. Также необходимо проверить, что на интерфейсах eth1 и eth2 нет никаких ip адресов. Теперь необходимо проделать тоже самое на labnode-2.
sudo vi /etc/sysconfig/network-scripts/ifcfg-bond0
Конфигурация bond0 интерфейса будет следующей:
TYPE=Bond
DEVICE=bond0
BOOTPROTO=static
IPADDR=10.0.12.30
PREFIX=24
BONDING_MASTER=yes
BONDING_OPTS="mode=0 miimon=100"
ONBOOT=yes
Конфиг eth1:
TYPE=Ethernet
DEVICE=eth1
MASTER=bond0
SLAVE=yes
Конфиг eth2:
TYPE=Ethernet
DEVICE=eth2
MASTER=bond0
SLAVE=yes
Перечитать конфигурационные файлы сетевых устройств и проверить после этого настройки сетевых интерфейсов:
sudo systemctl restart network
С labnode-1 необходимо проверить доступность labnode-2:
ping -c 4 10.0.12.30
Теперь на labnode-1 необходимо отключить eth1 и посмотреть его состояние:
sudo ip link set down eth1
ip address
И с labnode-2 проверить его доступность:
ping 10.0.12.20 -c 4
Если объединение интерфейсов настроено правильно, то узел будет доступен, даже после выключения одного из интерфейсов.
Задание 4. Настройка bridge интерфейса.
Ядро Linux имеет встроенный механизм коммутации пакетов между интерфейсами, и может функционировать как обычный сетевой коммутатор. Интерфейс Bridge представляет собой как сам виртуальный сетевой коммутатор, так и сетевой интерфейс с ip адресом, назначенным на порт этого коммутатора. Подключение должно быть выполнено по следующей схеме (рис. 3).

На labnode-1 требуется создать конфиг ifcfg-br0:
sudo vi /etc/sysconfig/network-scripts/ifcfg-br0
Мост будет иметь следующую конфигурацию:
TYPE=Bridge
DEVICE=br0
BOOTPROTO=static
IPADDR=10.0.12.20
PREFIX=24
STP=on
ONBOOT=yes
Spanning Tree Protocol (STP) нужен, чтобы избежать петель коммутации.
Интерфейс bond0, настроенный до этого, может быть интерфейсом этого сетевого коммутатора,
но в таком случае ip адрес уже будет назначен на интерфейс виртуального сетевого коммутатора,
и все настройки ip с интерфейса bond0 можно будет убрать.
Для этого в конфигурационный файл интерфейса bond0 также нужно добавить параметр
BRIDGE=br0. Также удалить из него параметры BOOTPROTO, IPADDR, PREFIX, ONBOOT
(можно просто закомментировать с помощью символа #, когда пригодятся, раскомментировать
их, убрав символ #):
sudo vi /etc/sysconfig/network-scripts/ifcfg-bond0
Перезагрузить сеть:
sudo systemctl restart network
Можно проверить результат. Для этого на labnode-2 выполнить следующую команду:
ip address
Проверить, что в результате вывода этой команды ip адрес будет назначен только на интерфейс br0, и он будет в состоянии UP. Если все правильно, то проверить доступность соседнего узла командой:
ping -c 4 10.0.12.20
Мост может подняться не сразу. Если что, необходимо подождать.
Задание 5. Создание VxLAN интерфейсов.
VxLAN является механизмом построения виртуальных сетей на основаниях тоннелей, поверх реальных сетей, но при этом позволяющим их разграничивать.
Подключение должно быть выполнено по следующей схеме (рис. 4).

На labnode-1 удалить конфигурацию моста br0:
sudo rm /etc/sysconfig/network-scripts/ifcfg-br0
И привести bond0 к прежнему виду:
TYPE=Bond
DEVICE=bond0
BOOTPROTO=static
IPADDR=10.0.12.20
PREFIX=24
BRIDGE=br0
BONDING_MASTER=yes
BONDING_OPTS="mode=0 miimon=100"
ONBOOT=yes
И перезагрузить сервер:
sudo reboot
После загрузки сервера проверить работу сети с узла labnode-2:
ping -c 4 10.0.12.20
На labnode-1 добавить интерфейс vxlan10:
sudo ip link add vxlan10 type vxlan id 10 dstport 0 dev bond0
Настроить коммутацию Linux Bridge:
sudo bridge fdb append to 00:00:00:00:00:00 dst 10.0.12.30 dev vxlan10
Назначить vxlan10 IP адрес и перевести его в состояние up:
sudo ip addr add 192.168.1.20/24 dev vxlan10
sudo ip link set up dev vxlan10
VxLAN работает как приложение. Пакеты инкапсулируются в udp, и для работы VxLAN требуется udp порт 8472. Открыть его в фаерволе:
sudo firewall-cmd --permanent --add-port=8472/udp
sudo firewall-cmd --reload
После нужно сделать все то-же самое на labnode-2. Добавить интерфейс vxlan10:
sudo ip link add vxlan10 type vxlan id 10 dstport 0 dev bond0
Настроить коммутацию Linux Bridge:
sudo bridge fdb append to 00:00:00:00:00:00 dst 10.0.12.20 dev vxlan10
Назначить vxlan10 IP адрес и перевести его в состояние up:
sudo ip addr add 192.168.1.30/24 dev vxlan10
sudo ip link set up dev vxlan10
Открыть порт 8472/udp в фаерволе:
sudo firewall-cmd --permanent --add-port=8472/udp
sudo firewall-cmd --reload
Протестировать соединение через vxlan. Для этого на labnode-1:
ping -c 4 192.168.1.30
Посмотреть на arp таблицу. Там можно увидеть соответствие mac адресов с ip адресами.
sudo arp
Нужно убедиться, что появилось приложение, которое слушает порт 8472.
ss -tulpn | grep 8472
Теперь необходимо добавить vxlan с другим тегом (20), и убедиться в том, что из него не будет доступа к vxlan с тегом 10 (пакеты будут отбрасываться из-за разных тегов). Перезагрузить labnode-2. Текущая настройка vxlan сбросится.
sudo reboot
На labnode-2 добавить интерфейс vxlan20 и настроить его:
sudo ip link add vxlan20 type vxlan id 20 dstport 0 dev bond0
sudo bridge fdb append to 00:00:00:00:00:00 dst 10.0.12.20 dev vxlan20
sudo ip addr add 192.168.1.30/24 dev vxlan20
sudo ip link set up dev vxlan20
ss -tulpn | grep 8472
Протестировать соединение через vxlan. Для этого на labnode-1:
ping 192.168.1.30 -c 4
Лабораторная работа 4. Основы виртуализации в Linux. QEMU/KVM.
Цель
Получить понимание принципа работы программ, используемых для виртуализации в операционной системе CentOS 7. Научиться работать с qemu.
Задачи
- Установить qemu.
- С использованием qemu-img провести базовые операции над образами.
- Скачать образ Cirros, запустить виртуальную машину и установить операционную систему на диск.
Note: Авторизация на всех узлах
Логин: labuser
Пароль: labpass1!
Схема виртуального лабораторного стенда

Задание 1. Установка QEMU.
Переключиться на проект [GROUP]:[team].lab:4-7. Включить labnode-1 и virt_viewer.
На labnode-1:
- Установить эмулятор аппаратного обеспечения различных платформ:
sudo yum install -y qemu-kvm
- Убедиться, что модуль KVM загружен (с помощью команд lsmod и grep):
lsmod | grep -i kvm

Задание 2. Управление образами дисков при помощи qemu-img.
Чтобы запускать виртуальные машины, QEMU требуются образы для хранения определенной файловой системы данной гостевой ОС. Такой образ сам по себе имеет тип некоторого файла, и он представляет всю гостевую файловую систему, расположенную в некотором виртуальном диске. QEMU поддерживает различные образы и предоставляет инструменты для создания и управления ими. Можно построить пустой образ диска с помощью утилиты qemu-img, которая должна быть установлена.
- Проверить какие типы образов поддерживаются qemu-img:
sudo qemu-img -h | grep Supported
- Создать образ qcow2 с названием system.qcow2 и размером 5 ГБ:
sudo qemu-img create -f qcow2 system.qcow2 5G
- Проверить что файл был создан:
ls -lah system.qcow2
- Посмотреть дополнительную информацию о данном образе:
sudo qemu-img info system.qcow2
Задание 3. Изменение размера образа.
Не все типы образов поддерживают изменение размера. Чтобы изменить размер такого образа необходимо преобразовать его вначале в образ raw при помощи команды преобразования qemu- img.
- Конвертировать образ диска из формата qcow2 в raw:
sudo qemu-img convert -f qcow2 -O raw system.qcow2 system.raw
- Добавить дополнительно 5 ГБ к образу:
sudo qemu-img resize -f raw system.raw +5GB
- Проверить новый текущий размер образа:
sudo qemu-img info system.raw
- Конвертировать образ диска обратно из raw в qcow2:
sudo qemu-img convert -f raw -O qcow2 system.raw system.qcow2
Задание 4. Загрузка образа Cirros.
Для загрузки образов с общедоступных репозиториев требуется утилита s3cmd. Загрузить необходимый образ, воспользовавшись s3cmd:
sudo yum install s3cmd
cd ~
sudo cp /var/lib/cloud/s3cfg .s3cfg
s3cmd -f get s3://lab3/cirros.img /tmp/
Задание 5. Создание виртуального окружения с помощью qemu-system.
- Для того, чтобы подключиться к виртуальной машине по протоколу удаленного рабочего стола Spice, нужно открыть порт 5900.
sudo firewall-cmd --permanent --add-port=5900-5930/tcp
sudo firewall-cmd --reload
- Посмотреть ip адрес вашего сервера
ip a
- Запустить систему при помощи qemu-system:
sudo /usr/libexec/qemu-kvm -hda /tmp/cirros.img \
-m 1024 -vga qxl -spice port=5900,disable-ticketing
- Открыть консоль виртуальной машины virt-viewer. Данная вирутальная машина имеет графическую оболочку, и позволяет взаимодействовать с графическими приложениям, создавая рабочее окружение клиента. Подключиться из виртуальной машины virt_viewer (Пользователь - labuser, пароль -labpass1!) к виртуальной машине. Для этого скачать программу remmina. Через менеджер Ubuntu Software (в списке слева) установить утилиту remmina, введя в поисковой строке её название, и нажав install.
Установить и открыть программу (название - Remmina). Для открытия программы Remmina – открыть меню приложений в левом нижнем углу, и из открывшегося списка приложений выбрать - Remmina. Подключаться по адресу spice://10.0.12.21:5900
- Залогиниться в Cirros. Дефолтные логин и пароль написаны в консоли (log - cirros/ pass- gocubsgo) ОС. Набрать команду uname -a. Посмотреть на версию ядра ОС. Выключить виртуальную машину, набрав
sudo poweroff
Лабораторная работа 5. Основы виртуализации в Linux. Libvirt.
Цель
Научиться работать с Libvirt и Virsh
Задачи
- Установить Libvirt.
- Настроить сетевой мост.
- Создать виртуальную машину.
- Провести базовые операции с виртуальной машиной.
Note: Авторизация на всех узлах
Логин: labuser
Пароль: labpass1!
Схема виртуального лабораторного стенда

Задание 1. Установка Libvirt и Virsh.
Необходимо установить несколько пакетов для виртуализации, которые не входят в базовую комплектацию системы. В проекте [GROUP]:[team]-lab:4-7, на labnode-1 нужно выполнить следующую команду:
sudo yum install -y libvirt virt-install
Задание 2. Настройка моста.
Установить пакет bridge-utils:
sudo yum install -y bridge-utils
Вывести на экран имеющиеся интерфейсы:
ip -c address
Открыть файл /etc/sysconfig/network-scripts/ifcfg-br0:
sudo vi /etc/sysconfig/network-scripts/ifcfg-br0
И добавить в него следующее содержимое:
TYPE=Bridge
DEVICE=br0
BOOTPROTO=static
ONBOOT=yes
IPADDR=10.0.12.21
PREFIX=24
GATEWAY=10.0.12.1
А в файл /etc/sysconfig/network-scripts/ifcfg-eth0 добавить параметр BRIDGE, убрать BOOTPROTO и ONBOOT,GATEWAY,IPADDR,NETMASK:
DEVICE=eth0
BRIDGE=br0
USERCTL=no
Перезагрузить сервер:
sudo reboot
Задание 3. Создание виртуальной машины.
Переместить образ cirros в /var/lib/libvirt/images/
sudo mv /tmp/cirros.img /var/lib/libvirt/images/
Следующая команда создаст новую KVM виртуальную машину
sudo virt-install --name cirros \
--ram 1024 \
--disk path=/var/lib/libvirt/images/cirros.img,cache=none \
--boot hd \
--vcpus 1 \
--network bridge:br0 \
--graphics spice,listen=0.0.0.0 \
--wait 0
Символ \ - обратная косая черта используется для экранирования специальных
символов в строковых и символьных литералах. В данном случае нужна, чтобы
переместить каретку на новую строку, для наглядности. После ее добавления в команду
можно нажать Enter, но строка не отправится на выполнение, а ввод команды
продолжится.
При ошибке в наборе команды, можно не набирать ее заново, а нажать стрелку вверх,
исправить ее, и снова нажать Enter
Подробнее о параметрах:
| Название парметра | Описание параметра |
|---|---|
| name | Имя виртуальной машины, которое будет отображаться в virsh |
| ram | Размер оперативной памяти в МБ |
| disk | Диск, который будет создан и подключен к виртуальной машине |
| vcpus | Количество виртуальных процессоров, которые нужно будет настроить для гостя |
| os-type | Тип операционной системы |
| os-variant | Название операционной системы |
| network | Определение сетевого интерфейса, который будет подключен к виртуальной машине |
| graphics | Определяет графическую конфигурацию дисплея. |
| cdrom | CD ROM устройство |
Далее необходимо подключиться из виртуальной машине virt_viewer (Пользователь - labuser, пароль -
labpass1!) к виртуальной машине через программу Remmina.
Открыть её (название - Remmina). Подключиться по адресу 10.0.12.21:5900, выбрав протокол SPICE
Вернуться в консоль labnode-1. Проверить состояние гостевой системы, используя команду
(Если в консоли написано “Domain installation still in progress”, то нажмите ^C):
sudo virsh list --all
Задание 4. Операции с виртуальной машиной.

Рассмотрим работу утилиты virsh. Чтобы подключиться к ВМ по протоколу удаленного доступа, используется следующая команда:
sudo virsh domdisplay cirros
Результатом исполнения этой команды будет адрес для подключения к графическому интерфейсу ВМ, с указанием номера порта. Получить информацию о конкретной ВМ можно так:
sudo virsh dominfo cirros
В результате чего будет выведена информация, об основных параметрах виртуальной машины. Выключить/включить ВМ можно с помощью команды:
sudo virsh destroy cirros
sudo virsh start cirros
Добавление ВМ в автозапуск происходит следующим образом:
sudo virsh autostart cirros
Теперь, виртуальная машина будет автоматически запускаться, после перезагрузки сервера. Кроме того, может потребоваться отредактировать XML конфигурацию ВМ:
sudo virsh edit cirros
* Чтобы выйти из редактора без сохранения - :q!
Необходимо выгрузить конфигурацию ВМ в XML в файл, используя команду:
sudo virsh dumpxml cirros | tee cirros.xml
Необходимо удалить ВМ, и убедиться, что её нет в списке виртуальных машин:
sudo virsh undefine cirros
sudo virsh destroy cirros
sudo virsh list --all
Для создания ВМ из XML существует следующая команда:
sudo virsh define cirros.xml
sudo virsh list --all
Лабораторная работа 6. Основы виртуализации в Linux. Отказоустойчивый кластер на базе Corosync/Pacemaker.
Цель
Получить базовые навыки в работе с пакетом управления виртуализацией Libvirt.
Задачи
- Настроить nfs клиент.
- Установить и настроить Corosync/Pacemaker.
- Подготовить XML ВМ.
- Создать ресурс.
Note: Логин/пароль на всех узлах
Логин: labuser
Пароль: labpass1!
Схема виртуального лабораторного стенда

Задание 1. Настройка nfs клиента
В проекте [GROUP]:[team]-lab:4-7, на labnode-1, labnode-2 и labnode-3 нужно зайти в файл /etc/fstab:
sudo vi /etc/fstab
И раскомментировать следующую строку (уберите символ # в начале строки):
10.0.12.18:/home/nfs/ /media/nfs_share/ nfs rw,sync,hard,intr 0 0
На всех трёх машинах установить пакет для работы с nfs и перемонтировать разделы, используя комманды:
sudo yum install -y nfs-utils
sudo mkdir /media/nfs_share
sudo mount -a
Задание 2. Установка Pacemaker и Corosync
Установка очень проста. На всех узлах нужно выполнить команду:
sudo yum install -y pacemaker corosync pcs resource-agents qemu-kvm libvirt virt-install
Далее поднять pcs. Тоже, на всех узлах:
sudo systemctl start pcsd
sudo systemctl enable pcsd
Открыть порты, необходимые для работы кластера (на всех узлах):
sudo firewall-cmd --permanent --add-port=5900-5930/tcp
sudo firewall-cmd --permanent --add-port=49152-49216/tcp
sudo firewall-cmd --permanent --add-service={high-availability,libvirt,libvirt-tls}
sudo firewall-cmd --reload
Для обращения к узлам по имени, а не по адресу удобнее прописать на всех узлах сопоставление ip адреса и его имени. В таком случае, для сетевого взаимодействия между узлами можно будет обращаться по его имени. Для того чтобы прописать это соответствие, необходимо открыть файл /etc/hosts:
sudo vi /etc/hosts
Прописать в нем следующее:
10.0.12.21 labnode-1 labnode-1.novalocal
10.0.12.22 labnode-2 labnode-2.novalocal
10.0.12.23 labnode-3 labnode-3.novalocal
Задайте пользователю hacluster пароль на всех узлах(сам пользователь был автоматически создан в процессе установки pacemaker).
echo password | sudo passwd --stdin hacluster
И, с помощью pcs создать кластер (на одном из узлов):
sudo pcs cluster auth labnode-1 labnode-2 labnode-3 -u hacluster -p password --force
sudo pcs cluster setup --force --name labcluster labnode-1 labnode-2 labnode-3
sudo pcs cluster start --all
Отключить fencing (в рамках работы он не рассматривается)
sudo pcs property set stonith-enabled=false
Включить автозапуск сервисов на всех трех машинах:
sudo systemctl enable pacemaker corosync --now
sudo systemctl status pacemaker corosync
Просмотреть информацию о кластере и кворуме:
sudo pcs status
sudo corosync-quorumtool
Задание 3. Настройка моста.
На labnode-1 уже создан мост. Сделать то же на labnode-2 и labnode-3. Открыть файл:
sudo vi /etc/sysconfig/network-scripts/ifcfg-br0
И добавить в него следующее содержимое для labnode-2:
TYPE=Bridge
DEVICE=br0
BOOTPROTO=static
ONBOOT=yes
IPADDR=10.0.12.22
PREFIX=24
GATEWAY=10.0.12.1
И добавить в него следующее содержимое для labnode-3:
TYPE=Bridge
DEVICE=br0
BOOTPROTO=static
ONBOOT=yes
IPADDR=10.0.12.23
PREFIX=24
GATEWAY=10.0.12.1
А в файл /etc/sysconfig/network-scripts/ifcfg-eth0 добавить параметр BRIDGE и убрать BOOTPROTO и ONBOOT:
DEVICE=eth0
#HWADDR=”оставить как было”
#ONBOOT=yes
TYPE=Ethernet
NAME=eth0
USERCTL=no
BRIDGE=br0
Перезагрузить сеть:
sudo systemctl restart network
Задание 4. Создание ресурса
Для начала, нужно отключить Selinux. Требуется зайти в файл /etc/selinux/config:
sudo vi /etc/selinux/config
И заменить значение параметра SELINUX с enforcing на permissive:
SELINUX = permissive
После чего перезагрузить ВМ:
sudo reboot
Сделать это нужно на labnode-1, labnode-2 и labnode-3.
В предыдущих заданиях был сделан дамп (копия) конфигурации виртуальной машины cirros на labnode-1.
ls -lah /home/labuser/cirros.xml
Необходимо зайти в него через vi:
sudo vi cirros.xml
И изменить в разделе
<source file='/var/lib/libvirt/images/cirros.img'/> ### эту строчку необходимо удалить
<source file='/media/nfs_share/cirros.img'/>
Можно воспользоваться поиском по файлу, набрав /, а затем то, что необходимо найти. Искать нужно <disk. То есть, набрать /<disk. Скопировать cirros.xml с labnode-1 на labnode-2 и labnode-3:
scp cirros.xml labnode-2:~
scp cirros.xml labnode-3:~
На labnode-1, labnode-2 и labnode-3 также переместить файл в /etc/pacemaker/
sudo mv cirros.xml /etc/pacemaker/
sudo chown hacluster:haclient /etc/pacemaker/cirros.xml
Теперь добавить сам ресурс:
sudo pcs resource create cirros VirtualDomain \
сonfig="/etc/pacemaker/cirros.xml" \
migration_transport=tcp meta allow-migrate=true
Просмотреть список добавленных ресурсов
sudo pcs status
sudo pcs resource show cirros
Проверить список виртуальных машин на узле, на котором запустился ресурс:
sudo virsh list --all
Проверить, что ресурс успешно запустился. Для этого из virt_viewer (Пользователь - Admin,
пароль - labpass1!) подключиться к нему через программу Reminna.
Подключаться по адресу spice://[address]:5900.
[address] - это IP адрес узла, на котором находится ресурс. Узнать его можно, набрав в
консоли соответствующего узла ip -c a.
Лабораторная работа 7. Основы виртуализации в Linux. Динамическая миграция ресурсов в отказоустойчивом кластере на базе Corosync/Pacemaker.
Цель
Получить базовые навыки в работе с пакетом управления виртуализацией Libvirt.
Задачи
- Настроить динамическую миграцию.
- Провести миграцию ресурса.
Note: Логин/пароль на всех узлах
Логин: labuser
Пароль: labpass1!
Проект: [GROUP]:[team]-lab:4-7 Схема виртуального лабораторного стенда

Задание 1. Настройка динамической миграции
Порты в фаерволе уже открыты, после этого настроить libvirt. Необходимо перейти в файл /etc/libvirt/libvirtd.conf
sudo vi /etc/libvirt/libvirtd.conf
Добавить туда три параметра:
listen_tls = 0
listen_tcp = 1
auth_tcp = "none"
Сохранить файл. После этого необходимо изменить файл /etc/sysconfig/libvirtd
sudo vi /etc/sysconfig/libvirtd
Добавить параметр:
LIBVIRTD_ARGS="--listen --config /etc/libvirt/libvirtd.conf"
Перезагрузить libvirt.
sudo systemctl restart libvirtd
Проделать эти операции на всех узлах.
Задание 2. Миграция ресурса
Нужно переместить ресурс на labnode-2:
sudo pcs resource move cirros labnode-2
На labnode-2 посмотреть статус кластера, и проверить список запущенных гостевых машин можно следующими командами:
sudo pcs status
sudo virsh list --all
Команда move добавляет ресурсу правило, заставляющее его запускаться только на указанном узле. Для того, чтобы очистить все добавленные ограничения - clear:
sudo pcs resource clear cirros
Из Remote Viewer необходимо проверить доступность ВМ на labnode-2. (spice://10.0.12.22:5900). Необходимо дождаться загрузки cirros. Переместить ресурс на labnode-1:
sudo pcs resource move cirros labnode-1
Посмотреть на результат:
sudo pcs status
sudo virsh list --all
При подключении к ресурсу, используя remmina, можно увидеть, что гостевая ОС не загружается с нуля, а уже включена. Ресурс был полностью перенесен на другой узел (включая оперативную память), а не просто отключён на первом и включен на втором.
Практические задания
Практическое задание №1. Создание виртуальной машины в новом проекте
Задачи:
- Подключиться к облачной инфраструктуре.
- Убедиться в наличии доступных сетей.
- Создать виртуальную машину.
- Настройка правил безопасности.
- Узнать адрес виртуальной машины.
- Подключиться к ВМ по ssh
1. Подключиться к облачной инфраструктуре.
Необходимо перейти по ссылке https://cloud.resds.ru. Для подключения использовать домен AD, а также учётную запись пользователя, используемую для подключения к WiFi СПбГУТ
Для выполнения практических занятий необходимо переключиться на проект [GROUP]:[team]-lab:sandbox.

2. Убедиться в наличии доступных сетей.
Открыть: проект -> сеть -> сети, и убедиться, что там есть сеть external-net (рис. 2)

3. Сгенерировать ключевую пару.


4. Создать виртуальную машину.

В открывшемся окне (рис. 6), во вкладке подробности ввести имя инстанса и нажать Следующая > внизу страницы.

В следующем меню (Источник) выбрать источник – образ, указать размер тома данных, выбрать удаление диска при удалении инстанса, выбрать необходимый вам образ из доступных (например Ubuntu-server-20.04:docker), и нажать справа от него стрелку вверх (рис. 7)
В следующем меню (тип инстанса) определить объем выделяемых виртуальной машине вычислительных ресурсов. Для этого нужно выбрать один из предопределённых типов инстансов (например small), и нажать справа от него стрелку вверх (рис. 8).
В меню сети выбрать нужную вам сеть, к которой будет подключена виртуальная машина (наличие сети было проверено в п.1). Если в инфраструктуре доступна только одна сеть, она будет выбрана автоматически, и выбирать ничего не нужно. (рис. 9)
Затем перейти к меню Ключевая пара, выбрать созданную ключевую пару, и нажать справа от неё стрелку вверх. (рис. 10)
После выполнения всех действий — нажать справа снизу кнопку «запустить инстанс» для создания и запуска виртуальной машины.
5. Настройка правил безопасности.
В открывшемся меню добавить правило для входящего трафика (рис. 12)
В открывшемся меню добавления правил (рис. 13), добавить правило для порта 80(tcp) Для этого выбрать:
Правило: «Настраиваемое правило TCP»
Направление: Входящий трафик
Порт: 80
Формат записи подключаемого диапазона адресов: CIDR
Сам подключаемый диапазон адресов: 0.0.0.0/0
Последняя запись означает разрешение подключения с любого адреса
После заполнения всех полей нажать кнопку «Добавить» в правом нижнем углу.
То же самое необходимо сделать для всех остальных портов.
6. Узнать адрес виртуальной машины.
7. Подключиться к ВМ по ssh
Открыть расположение сохраненного ключа, и два раза нажать на него, для запуска помощника авторизации pagent (pagent откроется в трее рабочего стола, пользователь не увидит запуск никаких приложений на рабочем столе) Запустить putty Открыть меню connection -> SSH -> Auth и в открывшемся меню в поле private key for authentication выбрать путь к сгенерированному ключу (рис. 16)
Открыть заново вкладку session, ввести адрес нашей ВМ и нажать Open (рис. 17)
В открывшемся окне терминала ввести имя пользователя cloudadmin. Это позволит получить удалённый доступ к вашей виртуальной машине.
Практическое задание №3.Создание сервиса облачного хранилища
Создание облачного сервиса.
Необходимо войти в панель управления облачной платформой – https://cloud.resds.ru/
В панели управления платформой необходимо выбрать проект [№ группы]-[№ бригады]:sandbox
1. Создание виртуального сервера.
Создать новый виртуальный сервер, на базе которого будет произведено создание образа собственного сервиса.
При создании сервиса задать образ - Ubuntu-20-Installer, при этом не создавая новый образ, и
используя имеющийся для установки необходимых компонентов сервера (рис. 1).

Тип инстанса выбрать Small
Выбрать сеть с внешним подключением (external-net)
После выбора сети появится возможность запуска инстанса - нажать «запустить инстанс» (справа
снизу).
-
Необходимо создать виртуальный диск, который будет являться образом нового сервиса. Для этого слева в панели выбрать меню – Диски -> Диски -> Создать диск (рис. 2)

Рис. 2 – создание диска. -
В появившемся меню задать имя диска и размер (20GB) и нажать – создать диск( рис. 3) Все

Рис. 3
6. Когда диск создан, необходимо подключить его к виртуальному серверу, на котором планируется создание нового сервиса. Для этого в раскрывающемся меню справа от нового диска выбрать «управление подключением дисков», а в открывшемся меню выбрать виртуальный сервер, к которому его необходимо подключить. (рис. 4)

-
Дальше можно переходить в меню установки нового сервиса. Для этого необходимо вернуться в меню инстансы(слева), и нажать на имя нашего нового инстанса, созданного в пункте 2. После этого необходимо открыть консоль этого инстанса, на вкладке – консоль. На самом деле перед вами установочное меню операционной системы ubuntu 20 в серверном исполнении, и возможностью установки сервисов.
-
В данной работе установка подразумевает под собой установку параметров в режиме по умолчанию. Для навигации по установочному меню используются кнопки клавиатуры: вверх-вниз – для перемещения фокуса выделения по пунктам меню, enter – для нажатия на необходимый пункт, пробел – для выбора пунктов в меню со списком выбора, Tab – для переключения между группами пунктов выбора.
-
в первом пункте по умолчанию выбран язык English – лучше его изменить на русский, для избегания проблем с локализацией. Для этого переместить фокус выделения на русский язык и нажать – enter.
-
В следующем меню оставить английскую расскладку клавиатуры и нажать готово
-
В следующем меню – сетевые соединения – оставить все параметры по умолчанию и нажать готово
-
В меню ввода адреса прокси сервера оставить пустым и нажать – готово
-
В в меню выбора зеркала для скачивания архивов ничего не менять и нажать готово
-
В в меню настройки дисковых устройств убедиться, что выбран диск на 20 гигабайт (созданный в пункте 5), и если он и выбран – нажать готово (рис. 5)

Рис. 5 -
в меню детальной настройки диска оставить всё без изменений и нажать – готово (в появившемся окне с предупреждением – нажать продолжить)
-
заполнить все поля имени пользователя и пароля (рис. 6).

| Server name | Ваше имя | Имя пользователя | Пароль |
|---|---|---|---|
| cloudstorage | labuser | labuser | labpass1! |
- установить OpenSSH server. Для этого в меню выбора при мигающем курсоре нажать – пробел – рис. 7

- В меню выбора функций выбрать nextcloud и нажать пробел. (рис. 8) После того, как выбор сделан – нажать готово.

Если всё было сделано корректно, установка должна успешно начаться. Когда установка дойдёт до «downloading and installing security update», можно удалять инстанс, так как эти компоненты не обязательны, а их установка может занять длительное время (рис. 9).

Для удаления необходимо в правом верхнем меню инстанса выбрать – удалить инстанс (рис. 10).

Теперь, когда виртуальный сервер удалён, можно приступать к развёртыванию собственного сервиса.
Развертывания из образа
В предыдущем шаге был подготовлен образ для развёртывания из него виртуального сервиса. Образ хорошо использовать по той причине, что его можно один раз создать, а потомиспользовать при необходимости развернуть конкретное приложение.
- необходимо сделать диск образа загрузочным. Для этого перейти в меню диски – диски – образ – редактировать диск (рис. 11)


- При выборе источника диска выбрать меню диск, и выбрать созданный на предыдущих этапах диск для развёртывания (рис. 13)

Выбрать тип виртуального сервера – small, и в качестве сети выбрать external-net
- После выборы сети – нажать запустить инстанс – всё, сервис готов, осталось дождаться, пока он запустится и подключиться к нему.
- Для подключения – в браузере набрать адрес виртуального сервиса (рис. 14).

- После подключения в браузере - задать логин и пароль администратора системы (можно использовать labuser и labpass1!), снять опцию – установить рекомендуемые приложения и нажать – завершить установку (рис. 15)

- После завершения настройки облачного сервиса вы сможете начать им пользоваться, он будет полностью под вашим контролем. Все файлы будут в меню файлы, вы сможете как загрузить их через браузер с вашего локального компьютера просто перетащив их, так и скачать их с облака.
P.S.
Nextcloud так же имеет приложения для различных платформ:
Для компьютера
Для android
Для iOS
При установке этого приложения вам нужно будет ввести адрес вашего сервиса, ваш логин, и ваш пароль который вы задали на этапе 6
Практическое задание №4.Wireguard
Для выполнения практических занятий необходимо переключиться на проект [GROUP]:[team]-lab:sandbox.
Пользовательская установка wireguard
Для начала надо развернуть новый инстанс (при ограничении ресурсов может потребоваться удалить все предыдущие инстансы) так, как это было сделанно в первой практической работе.
Зайти в режим привилегированного пользователя
sudo su
установить нужные пакеты:
apt update
apt install -y wireguard qrencode
Настройка системы
Разрешить перенаправление сетевых пакетов на уровне ядра. Для этого откройте файл /etc/sysctl.conf и добавьте в конец такие строки:
vi /etc/sysctl.conf
net.ipv4.ip_forward = 1
net.ipv6.conf.default.forwarding = 1
net.ipv6.conf.all.forwarding = 1
net.ipv4.conf.all.rp_filter = 1
net.ipv4.conf.default.proxy_arp = 0
net.ipv4.conf.default.send_redirects = 1
net.ipv4.conf.all.send_redirects = 0
Затем необходимо выполнить команду sysctl -p чтобы система перечитала конфигурацию:
sysctl -p
Генерация ключей сервера
Для сервера надо создать приватный и публичный ключ. Эти ключи, потом надо будет записать в конфигурационный файл сервера и клиента, сами файлы ключей вам не нужны, поэтому можете создавать их где хотите, например, в домашней папке. Так же полученный ключ можно записать в переменную окружения:
wg genkey | sudo tee server_private.key | wg pubkey | sudo tee server_public.key
Ключи созданы, утилита tee запишет их в файл, а также выведет на экран, что очень удобно для сохранения значения в переменную
Генерация ключей клиента
Аналогичным образом создаём ключи для клиента. Команда та же:
wg genkey | sudo tee client_private.key | wg pubkey | sudo tee client_public.key
Конфигурационный файл сервера
Конфигурационный файл сервера необходимо разместить по пути /etc/wireguard/wg0.conf и заполнить следующим образом(обратить внимание, что значение ключей в файле необходимо заменить):
vi /etc/wireguard/wg0.conf
[Interface]
Address = 10.10.10.1/24
ListenPort = 51820
PrivateKey = “содержимое файла server_private.key”
PostUp = iptables -A FORWARD -i wg0 -j ACCEPT; iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE; ip6tables -A FORWARD -i wg0 -j ACCEPT; ip6tables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
PostDown = iptables -D FORWARD -i wg0 -j ACCEPT; iptables -t nat -D POSTROUTING -o eth0 -j MASQUERADE; ip6tables -D FORWARD -i wg0 -j ACCEPT; ip6tables -t nat -D POSTROUTING -o eth0 -j MASQUERADE
MTU = 1420
[Peer]
PublicKey = “содержимое файла client_public.key”
AllowedIPs = 10.10.10.2/32
Файл разделен на две секции:
- Interface - настройка сервера;
- peer - настройка клиентов, которые могут подключаться к серверу, секций Peer может быть несколько.
В данном случае будет настроен сервер WireGuard для работы с IPv4, со следующими основными параметрами:
- Address - адрес сервера в сети VPN;
- ListenPort - порт, на котором будет ожидать подключения WireGuard;
- PrivateKey - приватный ключ сервера, сгенерированный ранее;
- PostUp - команда, которая выполняется после запуска сервера. В данном случае включается поддержка MASQUERADE для интерфейса enp0s8, а также разрешается прием пакетов на интерфейсе wg0. Сетевые интерфейсы вам придется заменить на свои.
- PostDown - выполняется после завершения работы WireGuard, в данном случае удаляет все правила, добавленные в PostUp.
Секции Peer содержат настройки клиентов, которые могут подключится к серверу:
- PublicKey - публичный ключ клиента, сгенерированный ранее;
- AllowedIPs - IP адрес, который может взять клиент. Обратите внимание, маска для IPv4 должна быть 32.
Теперь можно переходить к созданию конфигурационного файла непосредственно для клиента.
Конфигурационный файл клиента Конфигурационный файл клиента будет выглядеть примерно так:
vi client.conf
[Interface]
PrivateKey = “содержимое файла client_private.key”
Address = 10.10.10.2
DNS = 172.17.1.10
MTU = 1384
[Peer]
PublicKey = “содержимое файла server_public.key”
Endpoint = “ip адрес вашего инстанса”:51820
AllowedIPs = 0.0.0.0/0
Обратите внимание, что все ключи мы генерируем на сервере, а затем уже скидываем конфигурационный файл клиента на компьютер, который надо подключить к сети. Рассмотрим подробнее что за что отвечает:
- PrivateKey - приватный ключ клиента, сгенерированный ранее;
- Address - IP адрес интерфейса wg0 клиента;
- DNS - серверы DNS, которые будут использоваться для разрешения доменных имён;
- PublicKey - публичный ключ сервера, к которому надо подключится.
- Endpoint - здесь надо указать IP адрес сервера, на котором установлен WireGuard и порт;
- AllowedIPs - IP адреса, трафик с которых будет перенаправляться в сеть VPN, в данном примере выбраны все адреса.
Запуск сервера
Для запуска сервера используйте такую команду:
sudo systemctl start wg-quick@wg0
С помощью systemd можно настроить автозагрузку интерфейса:
sudo systemctl enable wg-quick@wg0
Подключение клиента
Вывести в консоль qr код, для подключения к vpn. Подключаться к ВПН с использованием клиента wireguard с мобильного телефона Для этого в консоли сгенерировать qr код:
qrencode -t ansiutf8 < client.conf
Далее необходимо проверить, что установленный сервер работает.
Инструкция по проверке подключения находится в конце данного руководства.
Установка wireguard из готового контейнера
Контейнер сам по себе является операционной системой минимального размера, с установленным внутри необходимым программным обеспечением. Контейнеры могут быть преднастроенными, и всё, что необходимо с ними сделать, это установить, передав нужные аргументы. Для работы с контейнерами чаще всего используются docker контейнеры, настроенные на необходимый режим работы путём передачи в них переменных окружения.
Перед установкой Docker нужно выполнить все необходимые настройки системы.
Установка Docker
Docker является набором утилит, для работы с контейнерами. Установку лучше всего выполнять из репозиториев самого Docker. Для начала необходимо установить набор утилит, помогающих работать со сторонними репозиториями.
sudo apt-get update
sudo apt-get install -y apt-transport-https ca-certificates curl gnupg lsb-release
Далее необходимо скачать ключи доступа к репозиториям (одной командой):
curl -fsSL https://download.docker.com/linux/ubuntu/gpg \
| sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
После этого необходимо добавить нужные репозитории (одной командой):
echo "deb [arch=$(dpkg --print-architecture) \
signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] \
https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
Добавив репозитории, можно установить все необходимые пакеты
sudo apt-get update
sudo apt-get install -y docker-ce docker-ce-cli containerd.io nftables
Запуск контейнера
Как только все необходимые приготовления сделаны, необходимо запустить контейнер с нужными параметрами (одной командой):
sudo docker run -ti -d --restart=always --network host \
--entrypoint "/wireguard-ui" -v /tmp/wireguard-ui:/data \
--privileged embarkstudios/wireguard-ui:latest \
--data-dir=/data --wg-listen-port=51820 \
--wg-endpoint="«ip адрес вашего виртуального сервера»:51820" \
--wg-allowed-ips=0.0.0.0/0 --wg-dns="172.17.1.10" \
--wg-device-name="wg0" --listen-address=":80" \
--nat --nat-device="eth0" --client-ip-range="10.0.8.1/24"
Настройка VPN тоннелей
Как только контейнер запущен, необходимо подключиться к web интерфейсу VPN сервера для того, чтобы добавить клиентов для подключения. Для этого необходимо открыть в браузере адрес:
http://«ip адрес вашего виртуального сервера»
В открывшемся окне нажать + в правом нижнем углу

В появившемся окне ввести имя клиента и нажать create
Клиент для подключения создан, так же создан конфигурационный файл для клиента и QR код, по которому можно скачать содержимое этого конфигурационного файла
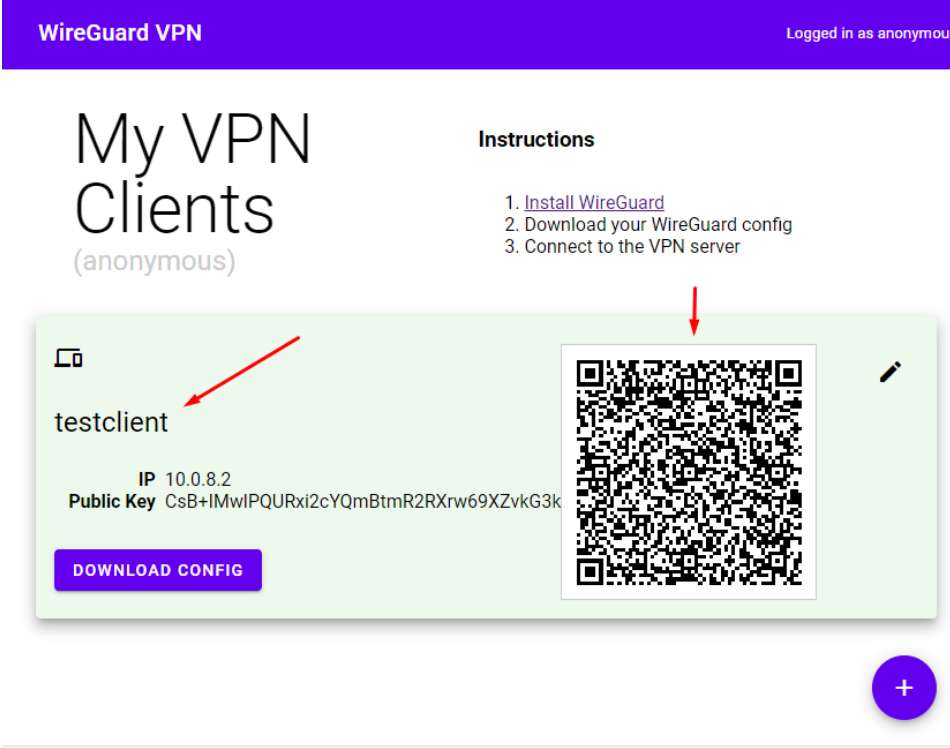 После создания клиента VPN сервер готов к подключениям внешних клиентов, и можно переходить к проверке.
После создания клиента VPN сервер готов к подключениям внешних клиентов, и можно переходить к проверке.
Автоматизация развёртывания облачного сервиса.
Для автоматического развёртывания облачного сервиса, необходимо при создании виртуальной машины дополнительно указать скрипт запуска и развёртывания необходимых сервисов. Для развёртывания этого сервиса необходимо создать скрипт, запускающий контейнер.
Добавлять в контейнер установку Docker не нужно, так как вы будете запускать из виртуального инстанса с предустановленным и запущенным Docker
Создание преднастроенной виртуальной машины
Необходимо создать виртуальную машину(в данной практической работе необходимо использовать образ ubuntu-server-20:docker), дополнительно заполнив раздел конфигурация
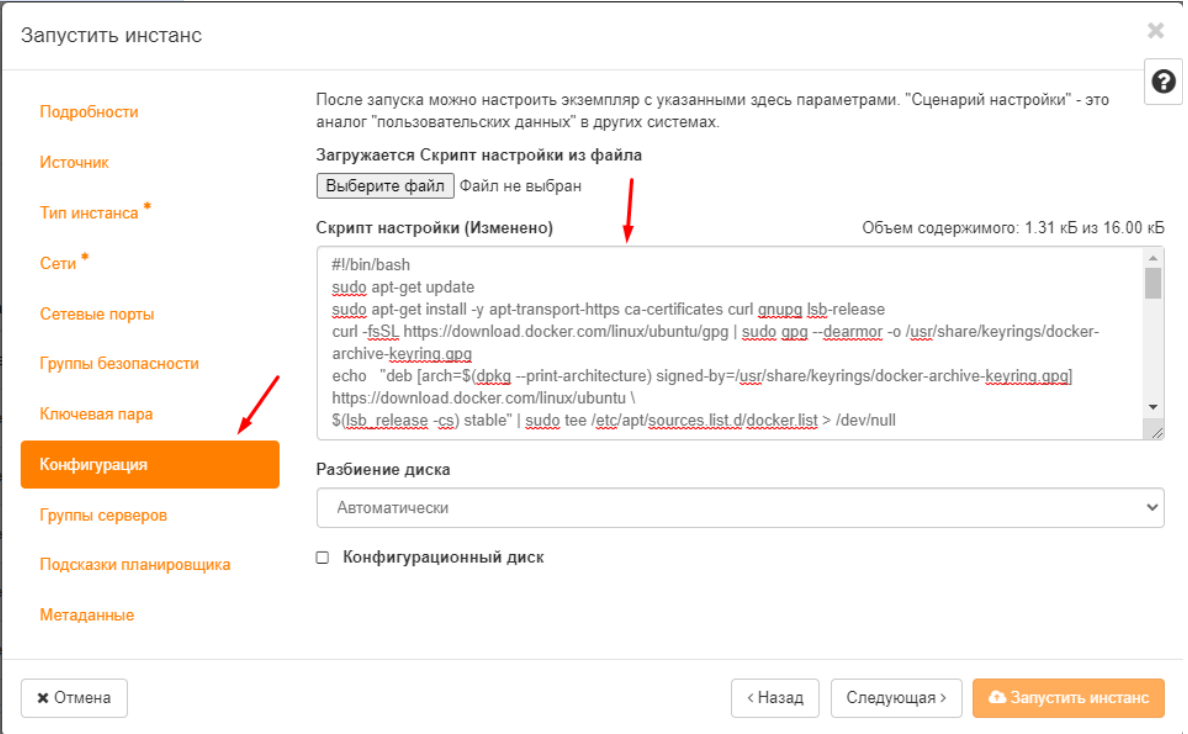 В разделе конфигурация в текстовое поле ввести скрипт, автоматизирующий установку и развёртывание облачного сервиса.
Сам скрипт автоматизации должен включать в себя запуск wireguard контейнера, и запись необходимых параметров в системные файлы.
В разделе конфигурация в текстовое поле ввести скрипт, автоматизирующий установку и развёртывание облачного сервиса.
Сам скрипт автоматизации должен включать в себя запуск wireguard контейнера, и запись необходимых параметров в системные файлы.
Пример конфига
#!/bin/bash
cat << EOF | sudo tee -a /etc/sysctl.conf
net.ipv4.ip_forward = 1
net.ipv6.conf.default.forwarding = 1
net.ipv6.conf.all.forwarding = 1
net.ipv4.conf.all.rp_filter = 1
net.ipv4.conf.default.proxy_arp = 0
net.ipv4.conf.default.send_redirects = 1
net.ipv4.conf.all.send_redirects = 0
EOF
sudo sysctl -p
ip=$(ip a | grep 172.17 | awk '{print $2}' | awk -F "/" '{print $1}')
sudo docker run -ti -d -p 80:80 -p 51820:51820 --restart=always --network host --entrypoint "/wireguard-ui" -v /tmp/wireguard-ui:/data --privileged embarkstudios/wireguard-ui:latest --data-dir=/data --wg-listen-port=51820 --wg-endpoint="$ip:51820" --wg-allowed-ips=0.0.0.0/0 --wg-dns="172.17.1.10" --wg-device-name="wg0" --listen-address=":80" --nat --nat-device="eth0" --client-ip-range="10.0.8.1/24"
sudo reboot -h now
После запуска виртуальной машины с указанным скриптом необходимо дождаться запуска виртуальной машины и находящихся на ней сервисов.
Настройка VPN тоннелей
Как только контейнер запущен, необходимо подключиться к web интерфейсу VPN сервера для того, чтобы добавить клиентов для подключения. Для этого необходимо открыть в браузере адрес:
http://«ip адрес вашего виртуального сервера»
В открывшемся окне нажать + в правом нижнем углу
В появившемся окне ввести имя клиента и нажать create
Клиент для подключения создан, так же создан конфигурационный файл для клиента и QR код, по которому можно скачать содержимое этого конфигурационного файла
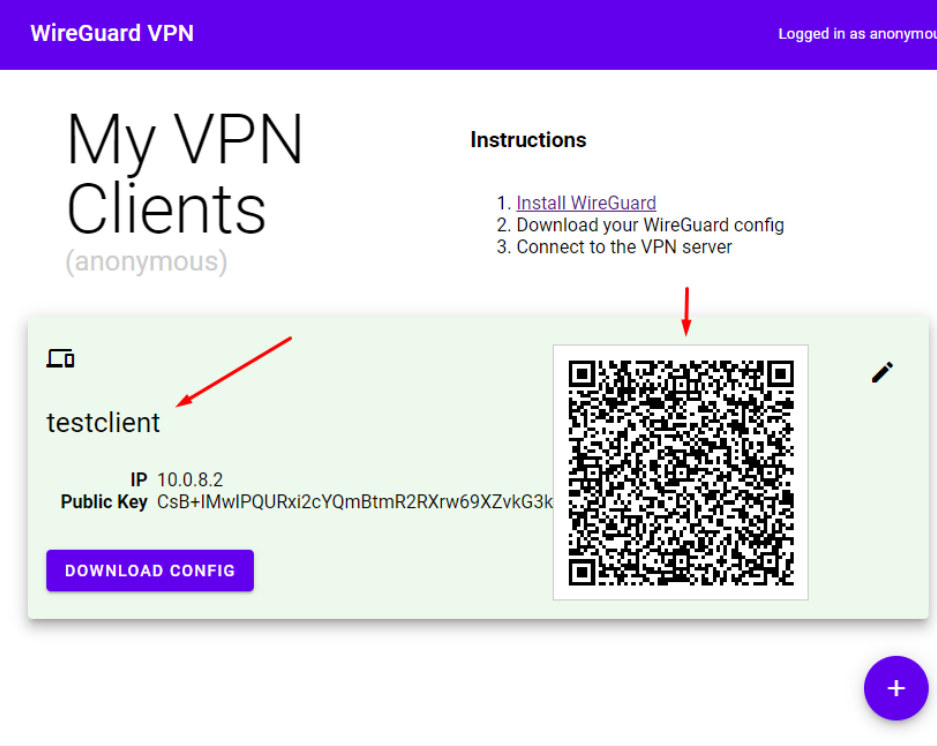 После создания клиента VPN сервер готов к подключениям внешних клиентов, и можно переходить к проверке.
После создания клиента VPN сервер готов к подключениям внешних клиентов, и можно переходить к проверке.
Проверка
Для начала необходимо установить клиент для подключения к VPN на мобильный телефон:
| Android | IOS |
|---|---|
 |
 |
Проверку необходимо выполнить со своего персонального устройства. Для начала убедиться, что вы работаете из сети СПбГУТ (Необходимо быть подключенным к WiFi сети) Перед подключением к VPN серверу необходимо проверить свой текущий ip адрес, под которым вас идентифицируют внешние службы. Сделать это можно открыв сайт ifconfig.resds.ru. На этой странице будет показано, c каким ip адресом вы обращайтесь как к этой странице.
Для проверки работоспособности VPN сервера необходимо к нему подключиться, и проверить, изменился ли ваш адрес, под которым вы обращаетесь к внешним службам. Если задание практической части было сделано правильно, то вы должны обращаться к внешним службам от адреса вашего VPN сервера.
Для подключения к VPN серверу необходимо:
- Открыть скачанное приложение WireGuard
- Нажать Add a tunnel для добавления VPN тоннеля
- Выбрать Create from QR code
- Отсканировать QR код с настройками вашего тоннеля
- В появившемся меню ввести произвольное имя тоннеля и нажать Save
- Подключиться к созданному тоннелю, нажав на переключатель в списке подключений Теперь снова необходимо открыть сайт ifconfig.resds.ru. Если значения изменились, можно сделать вывод о том, что ваш трафик идёт через сервер WireGuard
В случае возникновения проблем у WireGuard нет подробных логов, где можно было бы посмотреть какая ошибка произошла, а причин проблем может быть очень много. Чаще всего — это несоответствующие ключи, закрытый порт или неверный адрес сервера. Для исправления этих ошибок необходимо заново проверить все выполненные настройки.
Практическое задание №5-1. Запуск кластера Ceph
Схема виртуального лабораторного стенда
Для работы с облачной платформой необходимо прочитать инструкцию.
Переключиться на проект [GROUP]:[team]-lab:sandbox.
Подготовка системы
Запуск сети
Создание и настройка маршрутизатора
- Необходимо перейти в раздел
Сеть, в пунктеСети, у вас должна быть доступна сеть external-net, вторую сеть необходимо создать самостоятельно. Название для сети выбираем произвольно, напримерmy-internal-net.
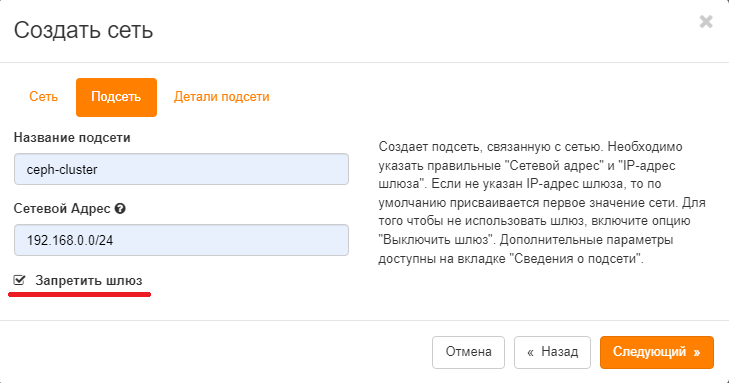
- Создаем подсеть в этой сети аналогично скриншоту ниже:
- В Деталях подсети отключаем DHCP

- В Деталях подсети отключаем DHCP

Создание и настройка портов для инстансов
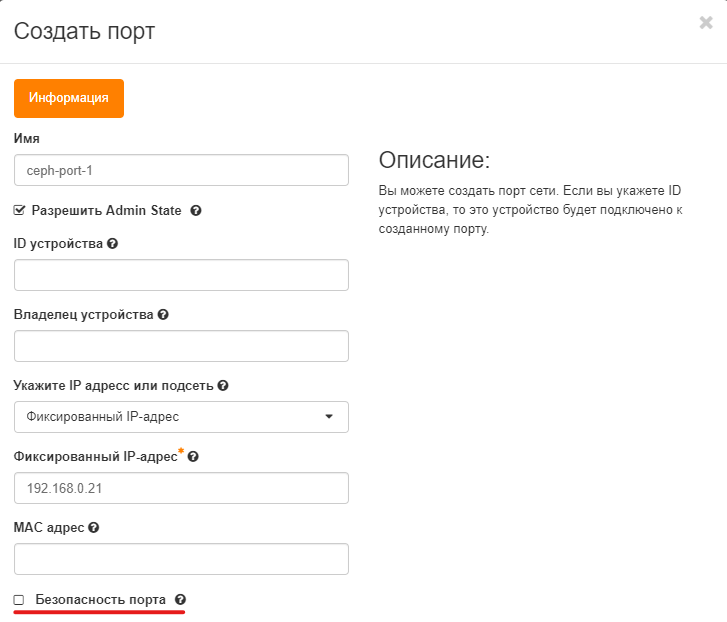
- Заходим в созданную ранее сеть ->
Порты:- Нажимаем
Создать порт - Заполняем поля формы:
- Имя: ceph-port-1
- IP адрес или подсеть: Фиксированный IP-адрес
- Фиксированный IP-адрес: 192.168.0.21
- Выключить Безопасность порта

- Аналогично создаём порты ceph-port-2 и ceph-port-3 с адресами 192.168.0.22 и 192.168.0.23 соответственно
- Нажимаем
Создание инстансов
-
Запустить 3 инстанса с характеристиками:
- Имена инстансов: ceph-01, ceph-02, ceph-03;
- Источник: Образ Ubuntu-server-20.04;
- Тип инстанса: small;
- Сети: external_net;
- Сетевые порты: port-ceph-1, port-ceph-2, port-ceph-3 для каждого инстанса соответственно.
-
Создать 3 диска по 2 Гб, подключить по одному диску на каждый инстанс. Список подключенных дисков может иметь следующий вид:

-
На каждом инстансе добавить записи в файл /etc/hosts (после подстановки адресов, кавычек быть не должно):
192.168.0.21 ceph-01 192.168.0.22 ceph-02 192.168.0.23 ceph-03 "внешний адрес узла #1" ext-ceph-01 "внешний адрес узла #2" ext-ceph-02 "внешний адрес узла #3" ext-ceph-03 -
Создать пару ключей на ceph-01 для соединения между инстансами(вводить никакие значения не требуется, на все вопросы оставить значение по умолчанию и нажать Enter)
ssh-keygen
Далее задать пароли для пользователя cloudadmin на узлах ceph-01,ceph-02,ceph-03
sudo passwd cloudadmin
пароль может быть любой
и скопировать публичный ключ ceph-01 на каждый инстанс(в том числи и на сам ceph-01 для автоматизации):
ssh-copy-id ceph-01
на второй:
ssh-copy-id ceph-02
И на третий:
ssh-copy-id ceph-03
Запуск кластера Ceph
Установка Ceph
На данном этапе необходимо установить пакет ceph на каждый узел.
Для этого нужно предварительно добавить ключ безопасности репозитория в список
доверенных и добавить репозиторий для скачивания указанных пакетов.
-
Для этого на каждом узле выполнить следующие команды:
sudo apt update sudo apt install -y ca-certificates wget -q -O- 'https://download.ceph.com/keys/release.asc' | sudo apt-key add - sudo apt-add-repository 'deb https://download.ceph.com/debian-quincy/ focal main' sudo apt update && sudo apt install ceph ceph-mds -y- Либо использовать скрипт:
Скрипт для запуска на ceph-01
#!/bin/bash for NODE in ceph-01 ceph-02 ceph-03 do ssh $NODE \ "sudo apt update; \ sudo apt install -y ca-certificates; \ wget -q -O- 'https://download.ceph.com/keys/release.asc' | sudo apt-key add -; \ sudo apt-add-repository 'deb https://download.ceph.com/debian-quincy/ focal main'; \ sudo apt update && sudo apt install ceph ceph-mds -y" done
- Либо использовать скрипт:
-
Проверить статус установки можно с помощью команды:
sudo ceph -v
Запуск демонов ceph-mon, ceph-mgr, ceph-osd, ceph-mds
Подготовка к запуску демонов
На узле ceph-01 необходимо выполнить следующие действия:
-
Получить уникальный идентификатор для кластера (можно с помощью команды
uuidgen):
ad56ab6d-7f7a-4ee4-8b02-9c7ef1ddb438- используется в качетсве примера -
Создать файл конфигурации для кластера по пути
/etc/ceph/ceph.conf. Необходимо вставить свои значения параметров: fsid, адреса интерфейсов внешней сети.
vi /etc/ceph/ceph.conf:
[global]
fsid = ad56ab6d-7f7a-4ee4-8b02-9c7ef1ddb438
mon initial members = ceph-01, ceph-02, ceph-03
mon host = ext-ceph-01, ext-ceph-02, ext-ceph-03
cluster network = 192.168.0.0/24
public network = 172.17.32.0/19
auth cluster required = cephx
auth service required = cephx
auth client required = cephx
osd pool default size = 3
osd pool default min size = 2
osd pool default pg num = 64
osd pool default pgp num = 64
osd crush chooseleaf type = 1
- Разберём параметры конфигурации:
-
fsid- идентификатор кластера -
mon initial members- имена узлов стартовых мониторов -
mon host- адреса стартовых мониторов -
cluster network- сеть кластера в формате CIDR, в которой будут передаваться heartbeat-сигналы, реплики данных между демонами OSD -
public network- внешняя сеть для взаимодействия с клиентами кластера -
auth cluster/service/client required- включение авторизации между демонами кластера и подключаемымиклиентами -
osd pool default size- количество реплик по умолчанию -
osd pool default min size- минимальное количество записанных реплик для объектов, чтобы подтвердить операцию ввода-вывода клиенту -
osd pool default pg num- количество групп размещения по умолчанию для пула -
osd pool default pgp num- количество групп размещения по умолчанию для размещения пула. PG и PGP должны быть равны -
osd crush chooseleaf type- максимальный уровень размещения кластера (при значении больше 1 имеется возможность создания групп узлов, таким образом можно разделить иерархию узлов на стойки, ЦОДы и другие физически разнесённые группы)
-
-
Создать связку ключей для своего кластера и сгенерировать секретный ключ монитора. Также создать связку ключей администратора,
client.adminпользователя и добавить пользователя в связку ключей. Создать связку ключейbootstrap-osd,client.bootstrap-osdпользователя и добавить пользователя в связку ключей:sudo ceph-authtool --create-keyring /tmp/ceph.mon.keyring --gen-key -n mon. --cap mon 'allow *' sudo ceph-authtool --create-keyring /etc/ceph/ceph.client.admin.keyring \ --gen-key -n client.admin --cap mon 'allow *' --cap osd 'allow *' \ --cap mds 'allow *' --cap mgr 'allow *' sudo ceph-authtool --create-keyring /var/lib/ceph/bootstrap-osd/ceph.keyring \ --gen-key -n client.bootstrap-osd --cap mon 'profile bootstrap-osd' \ --cap mgr 'allow r' -
Добавить сгенерированные ключи в связку
ceph.mon.keyring:sudo ceph-authtool /tmp/ceph.mon.keyring --import-keyring /etc/ceph/ceph.client.admin.keyring sudo ceph-authtool /tmp/ceph.mon.keyring --import-keyring /var/lib/ceph/bootstrap-osd/ceph.keyring -
Сгенерировать карту мониторов, используя имена узлов, внешние адреса (записи из файла
/etc/hostsздесь не работают) и FSID. Сохранить как /tmp/monmap:monmaptool --create --fsid ad56ab6d-7f7a-4ee4-8b02-9c7ef1ddb438 \ --add ceph-01 "внешний адрес узла #1" --add ceph-02 "внешний адрес узла #2" \ --add ceph-03 "внешний адрес узла #3" /tmp/monmap
Запуск ceph-mon
-
Необходимо скопировать файлы
/etc/ceph/ceph.conf,/etc/ceph/ceph.client.admin.keyring,/tmp/monmap,/tmp/ceph.mon.keyring,/var/lib/ceph/bootstrap-osd/ceph.keyringс ceph-01 на ceph-02 и ceph-03.-
Примеры выполнения данного пункта:
Пошаговые действия с описанием
-
Создадим папку
/tmp/ceph_filesи скопируем в неё все необходимые файлы:mkdir /tmp/ceph_files sudo cp /etc/ceph/ceph.conf /tmp/ceph_files/ceph.conf sudo cp /etc/ceph/ceph.client.admin.keyring /tmp/ceph_files/ceph.client.admin.keyring sudo cp /tmp/monmap /tmp/ceph_files/monmap sudo cp /tmp/ceph.mon.keyring /tmp/ceph_files/ceph.mon.keyring sudo cp /var/lib/ceph/bootstrap-osd/ceph.keyring /tmp/ceph_files/ceph.keyring -
Далее добавим общие права на чтение для всех файлов в папке и отправим эти файлы на ceph-02 и ceph-03. Удалим созданную ранее папку:
sudo chmod 644 /tmp/ceph_files/* scp -r /tmp/ceph_files/ ceph-02:~ scp -r /tmp/ceph_files/ ceph-03:~ sudo rm -rf /tmp/ceph_files -
На ceph-02 и ceph-03 выполняем следующие команды (возвращаем файлам их исходные права, копируем их по нужным путям и удаляем полученные файлы:
cd ~/ceph_files sudo chmod 600 ceph.client.admin.keyring ceph.mon.keyring ceph.keyring sudo cp ceph.conf /etc/ceph/ceph.conf sudo cp ceph.client.admin.keyring /etc/ceph/ceph.client.admin.keyring sudo cp monmap /tmp/monmap sudo cp ceph.mon.keyring /tmp/ceph.mon.keyring sudo cp ceph.keyring /var/lib/ceph/bootstrap-osd/ceph.keyring cd .. rm -rf ceph_files
Cкрипт для запуска на ceph-01
#!/bin/bash mkdir /tmp/ceph_files sudo cp /etc/ceph/ceph.conf /tmp/ceph_files/ceph.conf sudo cp /etc/ceph/ceph.client.admin.keyring /tmp/ceph_files/ceph.client.admin.keyring sudo cp /tmp/monmap /tmp/ceph_files/monmap sudo cp /tmp/ceph.mon.keyring /tmp/ceph_files/ceph.mon.keyring sudo cp /var/lib/ceph/bootstrap-osd/ceph.keyring /tmp/ceph_files/ceph.keyring sudo chmod 644 /tmp/ceph_files/* scp -r /tmp/ceph_files/ ceph-02:~ scp -r /tmp/ceph_files ceph-03:~ sudo rm -rf /tmp/ceph_files for NODE in ceph-02 ceph-03 do ssh $NODE \ "cd ~/ceph_files; \ sudo chmod 600 ceph.client.admin.keyring ceph.mon.keyring ceph.keyring; \ sudo cp ceph.conf /etc/ceph/ceph.conf; \ sudo cp ceph.client.admin.keyring /etc/ceph/ceph.client.admin.keyring; \ sudo cp monmap /tmp/monmap; \ sudo cp ceph.mon.keyring /tmp/ceph.mon.keyring; \ sudo cp ceph.keyring /var/lib/ceph/bootstrap-osd/ceph.keyring; \ cd ..; \ rm -rf ceph_files" done -
-
-
Далее создадим каталог для данных мониторов на узлах. Заполним демоны монитора картой мониторов и набором ключей. Это можно сделать с помощью следующих команд на каждом хосте:
sudo chown ceph:ceph /tmp/ceph.mon.keyring sudo -u ceph mkdir /var/lib/ceph/mon/ceph-$HOSTNAME sudo -u ceph ceph-mon --mkfs -i $HOSTNAME \ --monmap /tmp/monmap --keyring /tmp/ceph.mon.keyring sudo systemctl enable ceph-mon@$HOSTNAME --now- Либо использовать скрипт:
Скрипт для запуска на ceph-01
#!/bin/bash for NODE in ceph-01 ceph-02 ceph-03 do ssh $NODE \ "sudo chown ceph:ceph /tmp/ceph.mon.keyring; \ sudo -u ceph mkdir /var/lib/ceph/mon/ceph-$NODE; \ sudo -u ceph ceph-mon --mkfs -i $NODE \ --monmap /tmp/monmap --keyring /tmp/ceph.mon.keyring; \ sudo systemctl enable ceph-mon@$NODE --now" done
- Либо использовать скрипт:
-
Включим протокол
MESSENGER V2, отключим небезопасное использование клиентами глобальных идентификаторов и установим вывод предупреждений о малом свободном пространстве на основном диске хоста при остакте в 10% (иначе без этих параметров кластер может иметь статус HEALTH_WARN). Также установим параметр, позволяющий удалять пулы, в значениеtrue:sudo ceph mon enable-msgr2 sudo ceph config set mon auth_allow_insecure_global_id_reclaim false sudo ceph config set mon mon_data_avail_warn 10 sudo ceph config set mon mon_allow_pool_delete true -
Так как ещё не добавлено никаких устройств хранения, то в выводе состояния нас интересует только образовавшийся кворум мониторов:
sudo ceph -s
Запуск ceph-mgr
На каждом узле, где вы запускаете демон ceph-mon, вы также должны настроить демон ceph-mgr. Сначала
создадим ключ аутентификации для демона, поместим этот ключ в путь
/var/lib/ceph/mgr/ceph-$HOSTNAME/keyring и запустим демон ceph-mgr.
-
Для этого небоходимо выполнить данные действия на каждом хосте:
sudo ceph auth get-or-create mgr.$HOSTNAME mon 'allow profile mgr' osd 'allow *' mds 'allow *' sudo ceph auth get-or-create mgr.$HOSTNAME > /tmp/mgr.admin.keyring sudo -u ceph mkdir /var/lib/ceph/mgr/ceph-$HOSTNAME sudo cp /tmp/mgr.admin.keyring /var/lib/ceph/mgr/ceph-$HOSTNAME/keyring sudo chown -R ceph. /var/lib/ceph/mgr/ceph-$HOSTNAME sudo systemctl enable --now ceph-mgr@$HOSTNAME- Либо использовать скрипт:
Скрипт для запуска на ceph-01
#!/bin/bash for NODE in ceph-01 ceph-02 ceph-03 do MGR_PATH=/var/lib/ceph/mgr/ceph-$NODE; ssh $NODE \ "sudo ceph auth get-or-create mgr.$NODE \ mon 'allow profile mgr' osd 'allow *' mds 'allow *'; \ sudo ceph auth get-or-create mgr.$NODE > /tmp/mgr.admin.keyring; \ sudo -u ceph mkdir $MGR_PATH; \ sudo cp /tmp/mgr.admin.keyring $MGR_PATH/keyring; \ sudo chown -R ceph. $MGR_PATH; \ sudo systemctl enable --now ceph-mgr@$NODE" done
- Либо использовать скрипт:
-
На данном этапе мы можем увидеть статус запуска демонов менеджеров:
sudo ceph -s
Запуск ceph-osd
Ceph предоставляет ceph-volume утилиту, которая может подготовить логический том, диск или раздел
для использования с Ceph. Утилита ceph-volume создает идентификатор OSD путем увеличения
индекса. Кроме того, ceph-volume добавит новый OSD в карту CRUSH хоста.
-
На каждом хосте выполнить:
sudo ceph-volume lvm create --data /dev/vdb- Либо использовать скрипт:
Скрипт для запуска на ceph-01
#!/bin/bash for NODE in ceph-01 ceph-02 ceph-03 do ssh $NODE "sudo ceph-volume lvm create --data /dev/vdb" done
- Либо использовать скрипт:
-
На данном этапе кластер должен иметь статус HEALTH_OK:
sudo ceph -s -
Также подключенные OSD можно получить с помощью команды:
sudo ceph osd tree
Запуск услуг кластера
Создание пула и блочного устройства
-
Создадим пул
rbdи инициализируем его:sudo ceph osd pool create rbd 32 sudo rbd pool init rbd -
Получить список созданных пулов с помощью команды:
sudo ceph osd pool ls -
Создать блочное устройство в новом пуле:
sudo rbd create --size 10G --pool rbd rbd01
Проверка
-
Подключаем созданное устройство к ceph-01:
sudo rbd map rbd01 -
Получить список подлючённых устройств можно с помощью команды:
sudo rbd showmapped -
Установим файловую систему на подключенное устройство и примонтируем его к каталогу
/mnt/ceph_rbd:sudo mkfs.xfs /dev/rbd0 sudo mkdir /mnt/ceph_rbd sudo mount /dev/rbd0 /mnt/ceph_rbd/ -
На ceph-01 создать файл с произвольным текстом и поместить его в каталог
/mnt/ceph_rbd. Затем отмонтировать блочное устройство:echo "my text for ceph rbd" | sudo tee /mnt/ceph_rbd/rbd.txt sudo umount /dev/rbd0 sudo rbd unmap /dev/rbd/rbd/rbd01 -
На ceph-02 подключить использованное ранее блочное устройство и примонтировать его к каталогу
/mnt/ceph_rbd:sudo rbd map rbd01 sudo mkdir /mnt/ceph_rbd sudo mount /dev/rbd0 /mnt/ceph_rbd/ -
Проверить содержимое подключенного блочного устройства:
ls /mnt/ceph_rbd/ cat /mnt/ceph_rbd/rbd.txt -
Отмонтировать блочное устройство и удалить его, удалить пул:
sudo umount /dev/rbd0 sudo rbd unmap /dev/rbd/rbd/rbd01 sudo rbd rm rbd01 -p rbd sudo ceph osd pool delete rbd rbd --yes-i-really-really-mean-it
Практическое задание №5-2. Установка клиентской ВМ и настройка динамической миграции на базе Corosync/Pacemaker
Для выполнения практических занятий необходимо переключиться на проект [GROUP]:[team]-lab:sandbox.
Схема виртуального лабораторного стенда
Запуск ВМ с использованием Ceph RBD
Интеграция Ceph и libvirt
Установка libvirt
sudo apt install -y qemu-kvm virtinst libvirt-clients libvirt-daemon-system
Добавление пула Ceph в libvirt
-
Во-первых, нам нужно создать пул Ceph OSD специально для использования хранилища kvm, qemu, libvirt:
sudo ceph osd pool create libvirt-pool 64 64 sudo rbd pool init libvirt-pool -
Во-вторых, нам нужен пользователь Ceph для манипулирования только что созданным пулом.
sudo ceph auth get-or-create "client.libvirt" mon "profile rbd" osd "profile rbd pool=libvirt-pool"
Выполнить пункты 3-6 на каждом узле
-
Нам нужно добавить файл с секретом libvirt для аутентификации.
uuidgen->e6ca4cff-bf4f-4444-9089-8bd1304b3500- для libvirt секрета, использовать один для всех хостов
sudo vi /tmp/libvirt-secret.xml:<secret ephemeral='no' private='no'> <uuid>e6ca4cff-bf4f-4444-9089-8bd1304b3500</uuid> <usage type='ceph'> <name>client.libvirt secret</name> </usage> </secret> -
Встраиваем ключ авторизации пользователя Ceph в файл с секретом с указанным uuid.
sudo virsh secret-define --file "/tmp/libvirt-secret.xml" sudo rm -f "/tmp/libvirt-secret.xml" sudo virsh secret-set-value --secret "e6ca4cff-bf4f-4444-9089-8bd1304b3500" \ --base64 "$(sudo ceph auth get-key client.libvirt)" -
Нам также необходимо определить пул хранения RBD в libvirt. Сначала нам нужно создать файл определения пула хранения (вставить свои адреса внешних интерфейсов в теги host):
vi /tmp/libvirt-rbd-pool.xml:<pool type="rbd"> <name>libvirt-pool</name> <source> <name>libvirt-pool</name> <host name='ext-ceph-01' port='6789' /> <host name='ext-ceph-02' port='6789' /> <host name='ext-ceph-03' port='6789' /> <auth username='libvirt' type='ceph'> <secret uuid='e6ca4cff-bf4f-4444-9089-8bd1304b3500'/> </auth> </source> </pool> -
Теперь мы можем определить и запустить пул.
sudo virsh pool-define "/tmp/libvirt-rbd-pool.xml" sudo rm -f "/tmp/libvirt-rbd-pool.xml" sudo virsh pool-autostart "libvirt-pool" sudo virsh pool-start "libvirt-pool"- Проверить доступность созданного пула:
sudo virsh pool-list
- Проверить доступность созданного пула:
Запуск ВМ
-
Скачать образ
cirrosи скопировать его по пути/tmp/cirros.imgwget http://download.cirros-cloud.net/0.5.1/cirros-0.5.1-x86_64-disk.img sudo cp cirros-0.5.1-x86_64-disk.img /tmp/cirros.img -
Создать Ceph RBD для виртуальной машины:
sudo qemu-img convert -p -t none /tmp/cirros.img rbd:libvirt-pool/cirros sudo virsh pool-refresh libvirt-pool- Проверить доступность созданного образа:
sudo virsh vol-list libvirt-pool
- Проверить доступность созданного образа:
-
Создать ВМ:
sudo virt-install --name Test-VM --graphics none \ --vcpus 1 --memory 128 --disk "vol=libvirt-pool/cirros" \ --import --autostart -
Проверить работоспособность запущенной ВМ:
sudo virsh list --all sudo virsh console Test-VM
Настройка динамической миграции
Установка Pacemaker/Corosync
- На всех узлах нужно установить требуемые пакеты и запустить демон
pcsd:sudo apt install pacemaker corosync pcs resource-agents sudo systemctl enable --now pcsd
Запуск кластера
-
Задать пароль пользователя
haclusterна всех узлах (в примере используется парольpassword):sudo passwd hacluster -
Отредактировать раздел
nodelistфайла/etc/corosync/corosync.conf(на одном из узлов):nodelist { node { name: ceph-01 nodeid: 1 ring0_addr: ceph-01 } node { name: ceph-02 nodeid: 2 ring0_addr: ceph-02 } node { name: ceph-03 nodeid: 3 ring0_addr: ceph-03 } } -
С помощью pcs создать кластер (на одном из узлов):
sudo pcs host auth ceph-01 ceph-02 ceph-03 -u hacluster -p password sudo pcs cluster setup newcluster ceph-01 ceph-02 ceph-03 --force sudo pcs cluster start --all -
Отключить fencing (в рамках работы он не рассматривается):
sudo pcs property set stonith-enabled=false -
Включить автозапуск сервисов на всех трех машинах:
sudo systemctl enable pacemaker corosync -
Просмотреть информацию о кластере и кворуме:
sudo pcs status sudo corosync-quorumtool
Создание ресурса
-
Создать дамп созданной ВМ и затем удалить её:
sudo virsh dumpxml Test-VM > vm_conf.xml sudo virsh undefine Test-VM sudo virsh destroy Test-VM -
Скопировать дамп с ceph-01 на ceph-02 и ceph-03:
scp vm_conf.xml ceph-02:~ scp vm_conf.xml ceph-03:~ -
На ceph-01, ceph-02 и ceph-03 переместить файл в /etc/pacemaker/
sudo mv vm_conf.xml /etc/pacemaker/ sudo chown hacluster:haclient /etc/pacemaker/vm_conf.xml -
Теперь добавить сам ресурс:
sudo pcs resource create test-vm VirtualDomain \ config="/etc/pacemaker/vm_conf.xml" \ migration_transport=tcp meta allow-migrate=true -
Просмотреть список добавленных ресурсов:
sudo pcs status sudo pcs resource config test-vm -
Проверить список виртуальных машин на узле, на котором запустился ресурс:
sudo virsh list --all -
Проверить, что ресурс успешно запустился.
Настройка миграции
Выполнить действия на всех узлах
-
Необходимо отредактировать файл
/etc/libvirt/libvirtd.conf:listen_tls = 0 listen_tcp = 1 auth_tcp = "none" -
Отредактировать файл
/etc/default/libvirtd:libvirtd_opts="--config /etc/libvirt/libvirtd.conf" -
Запустить сокет
libvirt-tcp:sudo systemctl stop libvirtd && sudo systemctl start libvirtd-tcp.socket
Миграция ресурса
-
Нужно переместить ресурс на
ceph-02:sudo pcs resource move test-vm ceph-02 -
На ceph-02 посмотреть статус кластера, и проверить список запущенных гостевых машин можно следующими командами:
sudo pcs status sudo virsh list --all -
Команда move добавляет ресурсу правило, заставляющее его запускаться только на указанном узле. Для того, чтобы очистить все добавленные ограничения - clear:
sudo pcs resource clear test-vm
Практическое задание №5-3. Ceph FS, Ceph Dashboard
Для выполнения практических занятий необходимо переключиться на проект [GROUP]:[team]-lab:sandbox.
Использование файловой системы Ceph
Запуск ceph-mds
Чтобы услуга Ceph FS работала для клиентов, необходимо запустить демон сервера метаданных (MDS). Для этого создадим папку для демона, пользователя Ceph и запустим службу ceph-mds.
- Запустить демоны MDS на хостах ceph-02, ceph-03:
sudo mkdir -p /var/lib/ceph/mds/ceph-$HOSTNAME sudo ceph-authtool --create-keyring /var/lib/ceph/mds/ceph-$HOSTNAME/keyring \ --gen-key -n mds.$HOSTNAME sudo chown -R ceph. /var/lib/ceph/mds/ceph-$HOSTNAME sudo ceph auth add mds.$HOSTNAME osd "allow rwx" mds "allow" mon "allow profile mds" \ -i /var/lib/ceph/mds/ceph-$HOSTNAME/keyring sudo systemctl enable --now ceph-mds@$HOSTNAME- Либо использовать скрипт:
Скрипт для запуска на ceph-01
#!/bin/bash for NODE in ceph-02 ceph-03 do MDS_PATH=/var/lib/ceph/mds/ceph-$NODE; ssh $NODE \ "sudo mkdir -p $MDS_PATH; \ sudo ceph-authtool --create-keyring $MDS_PATH/keyring \ --gen-key -n mds.$NODE; \ sudo chown -R ceph. $MDS_PATH; \ sudo ceph auth add mds.$NODE osd 'allow rwx' mds 'allow' mon 'allow profile mds' \ -i $MDS_PATH/keyring; \ sudo systemctl enable --now ceph-mds@$NODE" done
- Либо использовать скрипт:
Создание файловой системы
На любом узле кластера необходимо выполнить следующие команды:
-
Чтобы запустить файловую систему ceph, нужно создать два пула: пул для данных и пул для метаданных:
sudo ceph osd pool create cephfs_data 64 sudo ceph osd pool create cephfs_metadata 64 -
Создадим файловую систему:
sudo ceph fs new cephfs cephfs_metadata cephfs_dataС помощью данных команд можно просмотреть статус файловой системы:
sudo ceph fs ls sudo ceph mds stat sudo ceph fs status cephfs -
Создадим пользователя для подключения к файловой системе и запишем ключ пользователя в отдельный файл:
sudo ceph fs authorize cephfs client.fsclient / rw -o /etc/ceph/ceph.client.fsclient.keyring sudo ceph auth get-or-create-key client.fsclient -o /etc/ceph/fsclient.secret -
Необходимо скопировать файлы
/etc/ceph/fsclient.secretи/etc/ceph/ceph.client.fsclient.keyringна остальные узлы.
Проверка
-
На каждом узле кластера необходимо выполнить следующие команды:
sudo mkdir /mnt/cephfs sudo mount -t ceph fsclient@.cephfs=/ /mnt/cephfs -o secretfile=/etc/ceph/fsclient.secret -
Проверить статус монтирования:
df -hT | grep ceph -
На ceph-01 создать файл с произвольным текстом и поместить его в каталог
/mnt/cephfs:echo "my text for ceph fs" | tee /mnt/cephfs/test.txt -
Проверить содержание файла на других узлах:
ls /mnt/cephfs/ cat /mnt/cephfs/test.txt
Динамическая миграция ВМ с использованием Ceph FS
-
Поместим образ
cirrosв созданную файловую систему:sudo cp /tmp/cirros.img /mnt/cephfs/cirros.img -
Запустим ВМ:
sudo virt-install --name cirros --graphics none \ --vcpus 1 --memory 128 --disk "vol=libvirt-pool/cirros" \ --import --autostart -
Проверим работоспособность запущенной ВМ:
sudo virsh list --all sudo virsh console cirros -
Дальнейшие действия аналогичны пунктам "Создание ресурса", "Миграция ресурса" практики 5.2.
Запуск Ceph Dashboard
-
В работающем кластере Ceph панель мониторинга Ceph активируется с помощью:
sudo ceph mgr module enable dashboard -
Сгенерируем и установим самоподписанный SSL сертификат:
sudo ceph dashboard create-self-signed-cert -
Чтобы иметь возможность войти в систему, вам необходимо создать учетную запись пользователя и связать ее хотя бы с одной ролью. Ceph предоставляет набор предопределенных системных ролей, которые вы можете использовать. Чтобы создать пользователя
adminс паролемpasswordи ролью администратора, можно воспользоваться следующими командами:echo "password" >> mypass sudo ceph dashboard ac-user-create admin -i mypass --force-password administrator rm mypass -
В Openstack в группе безопасности добавить правило для порта 8443/tcp.
-
С помощью команды
sudo ceph mgr servicesна одном из узлов кластера можно получить ссылки доступных сервисов. Пример вывода:{ "dashboard": "https://172.17.5.232:8443/" }