Базовая кафедра ИТТ
- Работа с текстовыми редакторами в Linux
- Работа с сетевой подсистемой Linux. Часть 1
- Работа с сетевой подсистемой Linux. Часть 2
- Работа с DNS
- Работа с дисковой подсистемой Linux
- Настройка сетевого хранилища
- Работа с виртуализацией: QEMU/KVM. Часть 1
- Работа с виртуализацией: QEMU/KVM. Часть 2
- Построение кластера
- Контейнеризация приложений
- Система контроля версий GIT
- Управление инфраструктурой. Terraform.
- Управление инфраструктурой. Ansible.
- Автоматизация сборки и развертывания приложений. Gitlab CI.
- Автоматизация развертывания приложений. Kubernetes.
Работа с текстовыми редакторами в Linux
Задачи:
- Подключиться к облачной инфраструктуре.
- Убедиться в наличии доступных сетей.
- Создать виртуальную машину.
- Настройка правил безопасности.
- Узнать адрес виртуальной машины.
- Подключиться к ВМ по ssh
- Установить пакет vim
- Пройти обучение работе с vim.
- Выполнить базовые действия с файлами и папками.
- Установить пакет wget.
- Научиться работать с переменными окружения.
- Создать нового пользователя и подключиться к нему. Поменять shell у пользователя.
- Изучить работу с текстом в Bash.
- Тренировка работы с grep
- Тренировка работы с sed
- Тренировка работы с awk
Задание 1. Подключиться к облачной инфраструктуре.
Необходимо перейти по ссылке https://cloud.resds.ru. Для подключения использовать домен AD, а также учётную запись пользователя, используемую для подключения к WiFi СПбГУТ
Для выполнения практических занятий необходимо переключиться на проект {username}.dev.

Задание 2. Убедиться в наличии доступных сетей.
Открыть: проект -> сеть -> сети, и убедиться, что там есть сеть external-net (рис. 2)

Задание 3. Сгенерировать ключевую пару.
При первом входе сгенерировать ключевую пару, для доступа к Linux виртуальным машинам. Открыть: Проект -> ключевая пара -> создать ключевую пару (рис. 3)


Задание 4. Создать виртуальную машину.
Открыть меню Проект > вычислительные ресурсы > инстансы > запустить инстанс (рис. 5)

В открывшемся окне (рис. 6), во вкладке подробности ввести имя инстанса и нажать Следующая > внизу страницы.

В следующем меню (Источник) выбрать источник – образ, указать размер тома данных, выбрать удаление диска при удалении инстанса, выбрать необходимый вам образ из доступных (например Ubuntu-server-20.04:docker), и нажать справа от него стрелку вверх (рис. 7)
В следующем меню (тип инстанса) определить объем выделяемых виртуальной машине вычислительных ресурсов. Для этого нужно выбрать один из предопределённых типов инстансов (например small), и нажать справа от него стрелку вверх (рис. 8).
В меню сети выбрать нужную вам сеть, к которой будет подключена виртуальная машина (наличие сети было проверено в п.1). Если в инфраструктуре доступна только одна сеть, она будет выбрана автоматически, и выбирать ничего не нужно. (рис. 9)
Затем перейти к меню Ключевая пара, выбрать созданную ключевую пару, и нажать справа от неё стрелку вверх. (рис. 10)
После выполнения всех действий - нажать справа снизу кнопку «запустить инстанс» для создания и запуска виртуальной машины.
Задание 5. Настройка правил безопасности.
Для работы с инстансом необходимо разрешить ему сетевое взаимодействие :80/TCP – HTTP, 22/TCP – SSH, 51820/UDP - other. Для этого нужно открыть Проект > Сеть > Группы безопасности > выбрать группу безопасности default и нажать – управление правилами (рис. 11)
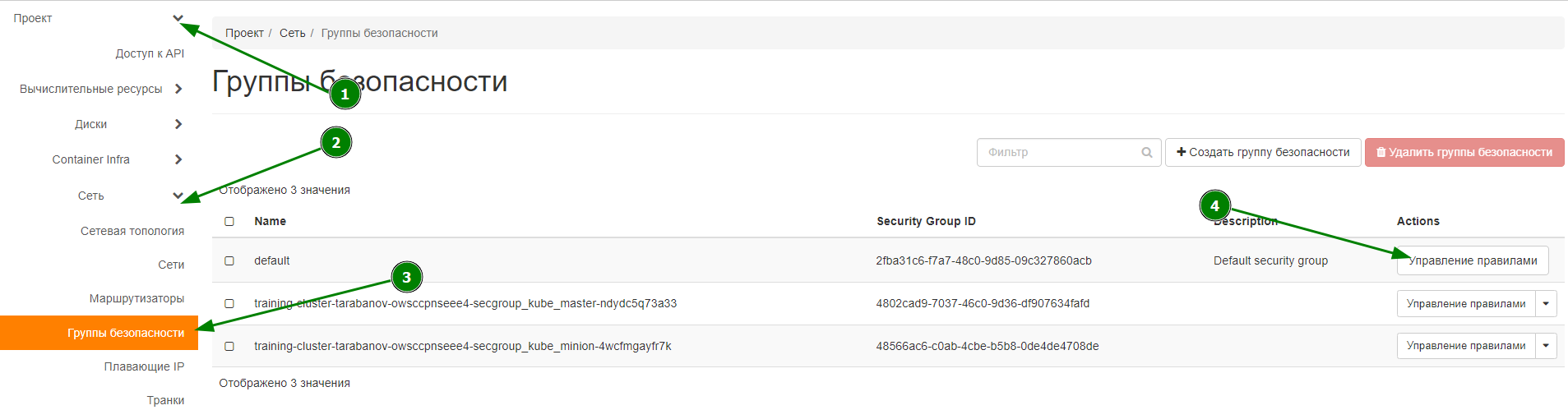
В открывшемся меню добавить правило для входящего трафика (рис. 12)
В открывшемся меню добавления правил (рис. 13), добавить правило для порта 80(tcp) Для этого выбрать: Правило: «Настраиваемое правило TCP» Направление: Входящий трафик Порт: 80 Формат записи подключаемого диапазона адресов: CIDR Сам подключаемый диапазон адресов: 0.0.0.0/0 Последняя запись означает разрешение подключения с любого адреса
После заполнения всех полей нажать кнопку «Добавить» в правом нижнем углу.
Тоже самое необходимо сделать для всех остальных портов.
Задание 6. Узнать адрес виртуальной машины.
Для этого вернуться во вкладку инстансы и в поле ip адрес будет ip адрес вашего виртуального инстанса (рис 14). Этот адрес понадобится в дальнейшем, для подключения к нему и его настройки.
Задание 7. Подключиться к ВМ по ssh
Linux
Для подключения в большинстве дистрибутивов уже установлены SSH-агенты и для подключения используя ключ достаточно добавить его в агент.
Для этого нужно выполнить команду, где pemkey.pem, это файл полученный вами на 3 пункте данной инструкции
ssh-add pemkey.pem
Для подключения в данном случае в терминале достаточно ввести команду:
ssh cloudadmin@172.17.5.1
адрес 172.17.5.1 необходимо заменить на ваш адрес полученный из пункта 6 инструкции
Windows OpenSSH
В Windows 10 c версии 1809 включен пакет OpenSSH, проверить это можно с помощью команды (выполняется с правами администратора):
Дальнейшие действия выполняются в PowerShell
Get-WindowsCapability -Online | ? Name -like 'OpenSSH.Client*'
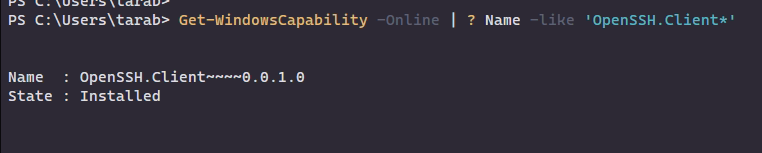
Если SSH клиент отсутствует (State: Not Present), его можно установить:
Add-WindowsCapability -Online -Name OpenSSH.Client*
Get-Service ssh-agent | Set-Service -StartupType Automatic -PassThru | Start-Service
Далее необходимо включить SSH-агент:
Start-Service ssh-agent
Добавить ключ можно с помощью команды:
ssh-add "C:\Users\{username}\.ssh\id_rsa"
username - имя вашего пользователя в системе
Теперь вы можете подключиться используя команду:
ssh cloudadmin@172.17.5.1
адрес 172.17.5.1 необходимо заменить на ваш адрес полученный из пункта 6 инструкции
Задание 8. Установка пакета VIM
Для установки, удаления, обновления пакетов в Ubuntu используется утилита apt. В процессе установки/обновления/удаления пакетов нужно будет подтвердить установку новых версий, нажав y. Или же использовать флаг -y. Необходимо установить пакет vim, в котором содержится необходимое обучающее руководство.
sudo apt install -y vim
Задание 9. Пройти обучение работе с vim
Ввести в консоли следующую команду, для запуска интерактивного обучающего курса по работе с VIM:
vimtutor ru
Пройти интерактивный курс до конца.
Задание 10. Работа с файловой системой.
- Создать директорию task01. Перейти в неё.
mkdir task01
cd task01
- Создать в домашнем каталоге текстовый файл user при помощи текстового редактора
vi, и заполнить его произвольными символами.
vi user
- Скопировать файл
userв новый файл с именемroot.
cp user root
- Посмотреть права доступа на файлы можно с помощью команды:
ls -l
- Задать владельца root и группу root на файл root. (sudo позволяет выполнять команды от
root; ввести пароль в диалоговом окне, при этом символы отображаться не будут; пароль -labpass1!)
sudo chown root:root root
- Переименовать (т.е. переместить с новым именем) файл
userв файлlock.
mv user lock
- На файл root поставить доступ на чтение и запись группе и владельцу остальным только на чтение.
sudo chmod 664 root
- На файл lock поставить доступ на чтение владельцу, группе и остальным пользователям убрать доступ на чтение запись и исполнение.
chmod 600 lock
- Вывести содержимое файла root в терминал.
cat root
- Отредактировать файл root случайным образом и вывести его содержимое в консоль.
sudo vi root
cat root
- Удалить каталог task01.
cd
sudo rm -rf task01
Задание 11. Установка пакетов.
Для установки, удаления, обновления пакетов в Ubuntu используется утилита apt.
В процессе установки/обновления/удаления пакетов нужно будет подтвердить установку новых версий, нажав y. Или же использовать флаг -y.
Для установки/удаления пакетов существуют команды:
sudo apt install -y package_name
sudo apt remove -y package_name
В качестве примера необходимо установить программу для скачивания файлов по web-протоколам - wget.
sudo apt install wget
Можно проверить версию установленного пакета:
wget –-version
Задание 12. Создание пользователей.
Создать нового пользователя newuser с паролем newpass1!. Сделать его администратором.
sudo adduser newuser
sudo passwd newuser # Ввести пароль newpass1!, при этом пароль отображаться не будет
sudo usermod -aG sudo newuser # Добавить пользователя newuser в группу sudo, что даст ему права на исполнение команд с sudo
Для того чтобы выполнять команды от имени пользователя newuser, необходимо сменить текущее окружение на окружение пользователя newuser командой - su. При этом нужно будет ввести пароль пользователя newuser.
su - newuser
Имя пользователя изменилось с labuser на newuser. Также, имя пользователя хранится в переменной окружения $USER. Просмотреть значение переменной можно с помощью команды echo.
echo $USER
Чтобы узнать, в каких группах состоит текущий пользователь, используется команда groups. В данном случае это должны быть группы newuser и sudo.
groups
Для выхода из оболочки используется команда exit. При этом выход идет в оболочку, запущенную пользователем labuser.
exit
Теперь нужно сменить оболочку, запускаемую по умолчанию при входе пользователя newuser. Чтобы узнать список доступных в системе оболочек, используется следующая команда:
cat /etc/shells
Сейчас должна быть запущена оболочка /bin/bash. Чтобы узнать, какая оболочка запущена сейчас, можно вывести на экран значение переменной $0.
echo $0
Чтобы просто запустить оболочку, достаточно просто набрать путь к ней. Запустить оболочку - sh, и вывести на экран переменную - $0. После выйти обратно в bash.
/bin/sh
echo $0
exit
Чтобы сменить оболочку по умолчанию для пользователя, можно отредактировать файл /etc/passwd, либо можно использовать утилиту usermod. Необходимо посмотреть, какая оболочка сейчас является оболочкой по умолчанию для пользователя newuser, сменить её на /bin/sh, и проверить изменения.
sudo grep newuser /etc/passwd # grep - программа для поиска по тексту. В данном случае, выведет все строки, содержащие newuser.
sudo usermod --shell /bin/sh newuser
sudo grep newuser /etc/passwd # Данная команда произведет поиск по файлу
# /etc/passwd, и отобразит в консоли все
# строки, в которых присутствует слово
# newuser. В этой же строке будет указано,
# какая оболочка используется данным
# пользователем
Теперь необходимо переключиться в режим работы от имени пользователя newuser, и проверить, какая оболочка используется. После выйти из этого режима, и удалить пользователя.
su - newuser
echo $0
exit
sudo userdel -r newuser # флаг r используется, когда вы хотите удалить также домашний каталог пользователя.
Задание 13. Работа с текстом в bash.
Для практики нужно воспользоваться текстовым файлом, специально созданным для выполнения задания - таблица подключений OpenVPN, состоящая из имени клиента, IP адреса, MAC адреса устройства и внешнего IP, с которого клиент подключился. Необходимо загрузить файл, воспользовавшись специальной утилитой curl:
sudo apt install curl -y
cd ~
curl -L -o clients.txt https://pastebin.com/raw/cEYa64Cz
Вывести содержимое файла в консоль (Тут для удобства можно пользоваться встроенными в консоль горячими клавишами: Ctrl+L - Очистить содержимое консоли, Shift+PgUp - Прокрутить консоль вверх, Shift+PgDn - Прокрутить консоль вниз).
cat ~/clients.txt
Для того чтобы вывести строки, содержащие подстроку, можно использовать grep. Необходимо вывести информацию о клиенте под номером 24 (grep - регистрозависимый, Client24 начинается с заглавной буквы).
grep Client24 ~/clients.txt
В результате исполнения команды должна быть выведена одна строка. Если было несколько строк, содержащих подстроку Client24, то в результате выведется несколько строк. Далее необходимо ввести команду:
grep Client2 ~/clients.txt
Необходимо попробовать понять, сколько будет выведено строк и почему именно они.
Помимо обычных строк grep поддерживает также регулярные выражения. При этом регулярные выражения должны экранироваться символом . С помощью регулярных выражений можно задать абсолютно любой паттерн. Относительно простой - вывести всех клиентов, имя которых заканчивается на 4. Точка в выражении означает любой символ.
grep Client\.4 ~/clients.txt
grep также умеет работать с пайплайном (вертикальная черта). С помощью пайплайна можно передавать вывод от одной программы другой, по принципу конвейера. Например, можно вывести текст через cat, и передать этот вывод на вход команды grep, для его обработки этой командой.
cat ~/clients.txt | grep Client\.4
Пайплайнов может быть несколько. Так, например, воспользовавшись программой AWK можно вывести только имя клиента и его внешний адрес - то есть первый и четвертый столбцы. (Внимание на пробел в двойных кавычках между номерами столбцов. Это разделитель, который будет между столбцами в конечном результате. Пробел можно заменить на любой другой символ, например, на дефис -, или символ табуляции \t. Можно попробовать это сделать)
Awk - это полноценный язык обработки текстовой информации с синтаксисом, напоминающим синтаксис языка C. Он обладает довольно широким набором возможностей, однако, мы рассмотрим лишь некоторые из них -- наиболее употребимые в сценариях командной оболочки. Awk "разбивает" каждую строку на отдельные поля. По-умолчанию, поля -- это последовательности символов, отделенные друг от друга пробелами, однако имеется возможность назначения других символов, в качестве разделителя полей. Awk анализирует и обрабатывает каждое поле в отдельности. Это делает его идеальным инструментом для работы со структурированными текстовыми файлами, осбенно с таблицами.
cat ~/clients.txt | grep Client\.4 | awk ‘{print $1” “$4}’
AWK также поддерживает функции в своем синтаксисе. Например, чтобы вывести имя клиента и MAC, при этом чтобы MAC печатался заглавными буквами, нужно использовать следующую конструкцию.
cat ~/clients.txt | grep Client\.4 | awk ‘{print $1” “toupper($3)}’
Далее необходимо вывести MAC адрес, чтобы он был разделён не двоеточиями, а дефисами, тогда можно воспользоваться sed. Нужно лишь задать параметры для замены. После этого результат можно вывести не в консоль, а в новый файл (набирать в одну строку):
Sed - это неинтерактивный строчный редактор. Он принимает текст либо с устройства stdin, либо из текстового файла, выполняет некоторые операции над строками и затем выводит результат на устройство stdout или в файл. Как правило, в сценариях, sed используется в конвейерной обработке данных, совместно с другими командами и утилитами.
cat ~/clients.txt | grep Client\.4 | awk ‘{print $1” “toupper($3)}’ | sed -r ‘s/:/-/g’ > newfile.txt
Задание 14. Тренировка работы с grep
Устанавливаем пакет, git для работы с git репозиториями:
sudo apt install -y git
Копируем репозиторий с GitHub и устанавливаем тренажер:
git clone https://github.com/learnbyexample/TUI-apps.git
cd TUI-apps/GrepExercises
sudo apt install -y python3 python3-pip python3-venv
python3 -m venv textual_apps
cd textual_apps
source bin/activate
pip install grepexercises
Запускаем тренажер
grepexercises
Задание 15. Тренировка работы с sed
Переходим :
cd ../sedexercises
python3 -m venv textual_apps
cd textual_apps
source bin/activate
pip install sedexercises
Запускаем тренажер
sedexercises
Задание 16. Тренировка работы с awk
Переходим :
cd ../awkexercises
python3 -m venv textual_apps
cd textual_apps
source bin/activate
pip install awkexercises
Запускаем тренажер
awkexercises
Работа с сетевой подсистемой Linux. Часть 1
Схема виртуального лабораторного стенда

Задание 0. Построение стенда
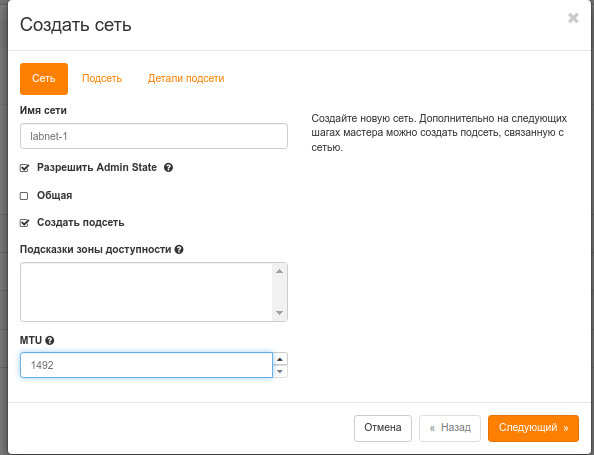
1. Создать 2 виртуальные сети:
- lab_net1
- lab_net2
| Название сети/подсети | Сетевой адрес | mtu |
|---|---|---|
| labnet-1 | 10.0.12.0/24 | 1492 |
| labnet-2 | 10.0.12.0/24 | 1492 |
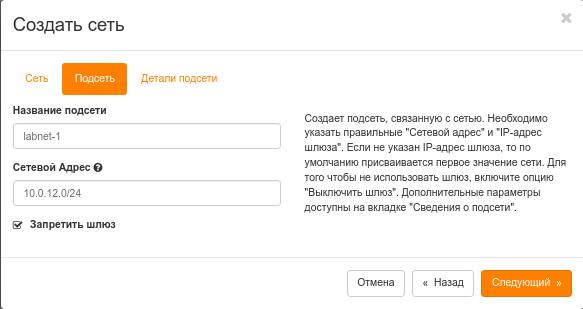
При создании подсети необходимо выбрать пункт "Запретить шлюз"
Пример создания сетей
Для создания сети нужно перейти в сети:
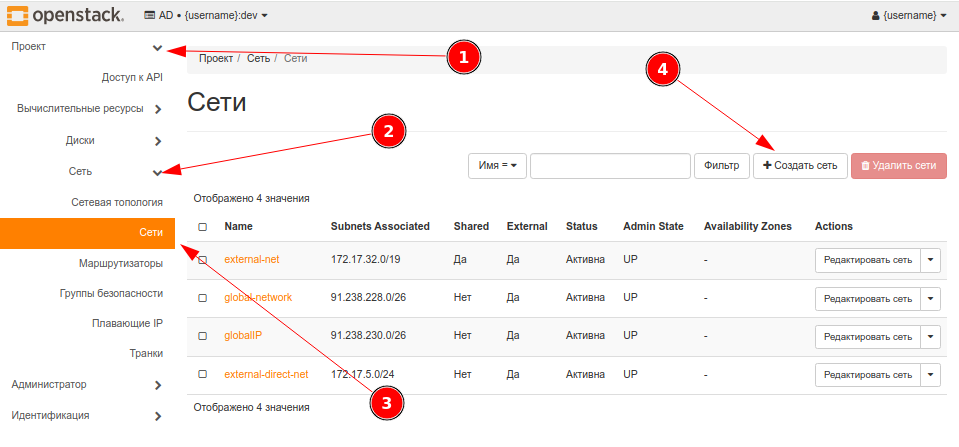
Создать порты для дальнейшего использования
| название сети | Название порта | ip адрес | Безопасность порта |
|---|---|---|---|
| labnet-1 | port-1-1 | 10.0.12.20 | Отключена |
| labnet-1 | port-1-2 | 10.0.12.30 | Отключена |
| labnet-2 | port-2-1 | 10.0.12.21 | Отключена |
| labnet-2 | port-2-2 | 10.0.12.31 | Отключена |
Пример создания порта
Cоздать порты: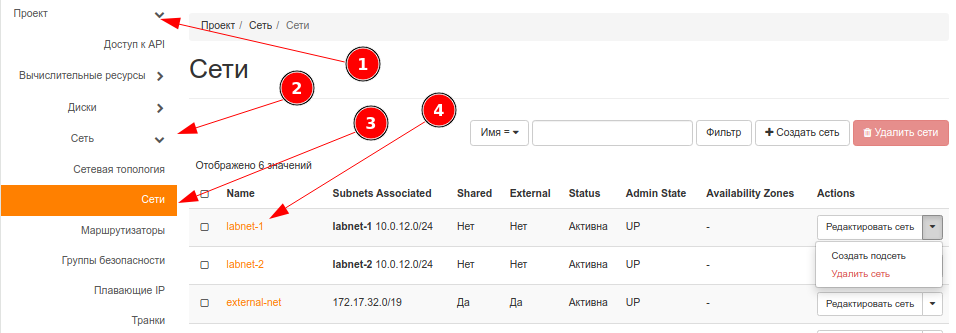
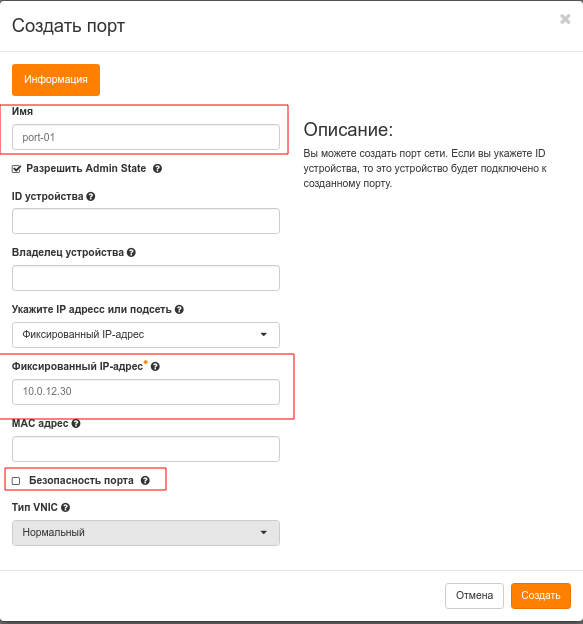
2. Создать виртуальные машины для работы
| Название виртуальной машины | Источник | Тип инстанса | Сети | Сетевые порты |
|---|---|---|---|---|
| labnode-1 | Образ-CentOS-7:RECSDS | small | external-net | port-1-1,port-2-1 |
| labnode-2 | Образ-Ubuntu-server20.04 | small | external-net | port-1-2,port-2-2 |
Задание 1. Установка статического IP адреса физическому интерфейсу
Подключение должно быть выполнено по следующей схеме (рис. 1).

Воспользоваться утилитой ip. Для того чтобы увидеть существующие в системе интерфейсы, набрать команду:
ip address
Там же будут отображены основные параметры этих сетевых интерфейсов.
Команда ip позволяет использовать короткие имена команд. В данном случае, вместо ip address можно использовать команду
ip a
В случае правильного выполнения команд (для всех команд кроме ip address) утилита ip не будет
возвращать никакого значения. В случае, если команда выполнена неправильно, будет
возвращена соответствующая ошибка.
Задать интерфейсу eth1 IP адрес:
sudo ip address add 10.0.12.20/24 dev eth1
Изменить состояние на up.
sudo ip link set up dev eth1
Посмотреть изменения (состояние устройства eth1 должно измениться на UP):
ip address
Подключиться к labnode-2. Установить интерфейсу eth1 IP адрес: Необходимо привести конфиг на labnode-2 к его минимальной конфигурации необходимой для подключения:
sudo vi /etc/netplan/50-cloud-init.yaml
И привести его к следующему виду:
network:
version: 2
ethernets:
eth0:
dhcp4: true
mtu: 9000
Задать адрес интерфейса eth1
sudo ip address add 10.0.12.30/24 dev eth1
Изменить состояние на up:
sudo ip link set up dev eth1
С labnode-1 проверить доступность labnode-2:
ping -c 4 10.0.12.30
После перезагрузки сервера, или сервиса сети все изменения отменяются. Перезагрузить оба сервера, и посмотреть на состояние интерфейсов (необходимо проверить, сохранились ли на интерфейсе адреса, заданные предыдущими командами):
reboot
# Дождаться перезагрузки системы
ip address
Задание 2. Настройка статического адреса через конфигурационные файлы
Подключение должно быть выполнено по следующей схеме (рис. 1). Для того чтобы изменения оставались в силе, нужно настроить интерфейс через конфигурационный файл. Тогда настройки будут загружаться при старте системы. Создать конфигурацию интерфейса eth1 на labnode-1:
sudo vi /etc/sysconfig/network-scripts/ifcfg-eth1
И привести его к следующему виду:
TYPE=Ethernet
DEVICE=eth1
BOOTPROTO=static
IPADDR=10.0.12.20
PREFIX=24
ONBOOT=yes
Основные параметры:
- TYPE - Тип сетевого интерфейса
- NAME - Имя интерфейса
- DEVICE - Устройство, которое интерфейс использует
- BOOTPROTO - если этот параметр static, то интерфейс не будет автоматически получать адрес от сети, маску и другие параметры подключения. В случае необходимости автоматического получения адреса – необходимо указать значение этого параметра -dhcp.
- ONBOOT - включать ли интерфейс при загрузке.
- IPADDR - IP-адрес
- DNS1 - DNS, через который обращаться к доменам. Можно указать несколько параметров: DNS1, DNS2...
- PREFIX - префикс, другой способ задания маски сети. Для префикса 24 маска будет 255.255.255.0
- GATEWAY - шлюз
Все остальные параметры являются необязательными в данной лабораторной работе, и должны быть удалены.
Скопировать файл ifcfg-eth1 с именем ifcfg-eth2:
sudo cp /etc/sysconfig/network-scripts/ifcfg-eth1 /etc/sysconfig/network-scripts/ifcfg-eth2
Отредактировать его с помощью редактора vi:
sudo vi /etc/sysconfig/network-scripts/ifcfg-eth2
И привести его содержимое к следующему виду:
TYPE=Ethernet
DEVICE=eth2
BOOTPROTO=static
IPADDR=10.0.12.21
PREFIX=24
ONBOOT=yes
Перезагрузить сеть и посмотреть интерфейсы:
sudo systemctl restart network
ip address
Далее необходимо настроить интерфейсы на узле labnode-2используя netplan. Сначала необходимо отредактировать создать конфигурацию интерфейса eth1 на labnode-2:
sudo vi /etc/netplan/51-eth1.yaml
И привести его к следующему виду:
network:
version: 2
ethernets:
eth1:
addresses:
- 10.0.12.30/24
mtu: 1492
Скопировать файл 51-eth1.yaml с именем 51-eth2.yaml:
sudo cp /etc/netplan/51-eth1.yaml /etc/netplan/52-eth2.yaml
Отредактировать его через vi:
sudo vi /etc/netplan/52-eth2.yaml
И привести к следующему виду:
network:
version: 2
ethernets:
eth2:
addresses:
- 10.0.12.31/24
mtu: 1492
Примените конфигурацию и посмотреть интерфейсы:
sudo netplan try
ip address
Проверить доступность интерфейсов:
(labnode-1) ping -c 4 10.0.12.30
(labnode-1) ping -c 4 10.0.12.31
(labnode-2) ping -c 4 10.0.12.20
(labnode-2) ping -c 4 10.0.12.21
Задание 3. Настройка объединения интерфейсов.
"Объединение" (bonding) сетевых интерфейсов - позволяет совокупно собрать несколько портов в одну группу, эффективно объединяя пропускную способность в одном направлении. Например, вы можете объединить два порта по 100 мегабит в 200 мегабитный магистральный порт.
<I>В некоторых случаях интерфейсы после перезапуска сетевой службы не удаляют ip адреса, что связано с особенностью работы up/down скриптов. В таком случае в системе на разных интерфейсах может присутствовать одинаковый ip адрес (проверить можно командой ip address). Для решения этой проблемы необходимо отчистить все адреса на интерфейсе. Сделать это можно как просто удалив конкретный адрес с интерфейса, так и воспользоваться специальной командой, которая очистит все имеющиеся на нём адреса:
sudo ip address flush dev eth1
sudo ip address flush dev eth2
Подключение должно быть выполнено по следующей схеме (рис. 2).

Для того, чтобы создать интерфейс bond0, нужно создать файл конфигурации:
sudo vi /etc/sysconfig/network-scripts/ifcfg-bond0
Конфигурация bond0 интерфейса на labnode-1 будет следующей:
TYPE=Bond
DEVICE=bond0
BOOTPROTO=static
IPADDR=10.0.12.20
PREFIX=24
BONDING_MASTER=yes
BONDING_OPTS="mode=0 miimon=100"
ONBOOT=yes
Это создаст сам bond0 интерфейс. Но нужно также назначить физические интерфейсы eth1 и eth2, как подчиненные ему. Необходимо изменить конфигурационный файл eth1:
sudo vi /etc/sysconfig/network-scripts/ifcfg-eth1
И привести его к следующему виду:
TYPE=Ethernet
DEVICE=eth1
MASTER=bond0
SLAVE=yes
То же самое сделать и с eth2:
sudo vi /etc/sysconfig/network-scripts/ifcfg-eth2
TYPE=Ethernet
DEVICE=eth2
MASTER=bond0
SLAVE=yes
Перезагрузить сеть.
sudo systemctl restart network
Посмотреть, что получилось:
ip a
В полученном выводе интерфейсы eth1 и eth2 должны быть в подчиненном режиме (SLAVE), а интерфейс bond0 должен иметь ip адрес и находиться в состоянии UP. Также необходимо проверить, что на интерфейсах eth1 и eth2 нет никаких ip адресов. Теперь необходимо проделать аналогичные манипуляции на labnode-2.
Удалить содержимое файлов 51-eth1.yaml и 52-eth2.yaml
rm -rf /etc/netplan/51-eth1.yaml
rm -rf /etc/netplan/52-eth2.yaml
Настроить интерфейс bond0 для создания отказоустойчивого подключения. Для этого открыть новый файл конфигурации 53-bond0.yaml:
sudo vi /etc/netplan/53-bond0.yaml
Конфигурация bond0 интерфейса будет следующей:
network:
version: 2
ethernets:
eth1: {}
eth2: {}
bonds:
bond0:
mtu: 1492
interfaces:
- eth1
- eth2
parameters:
mode: balance-rr
mii-monitor-interval: 100
addresses:
- 10.0.12.30/24
Перечитать конфигурационные файлы сетевых устройств и проверить после этого настройки сетевых интерфейсов:
sudo netplan try
С labnode-1 необходимо проверить доступность labnode-2:
ping -c 4 10.0.12.30
Теперь на labnode-1 необходимо отключить eth1 и посмотреть его состояние:
sudo ip link set down eth1
ip address
И с labnode-2 проверить его доступность:
ping 10.0.12.20 -c 4
Если объединение интерфейсов настроено правильно, то узел будет доступен, даже после выключения одного из интерфейсов.
Задание 4. Настройка bridge интерфейса.
Ядро Linux имеет встроенный механизм коммутации пакетов между интерфейсами, и может функционировать как обычный сетевой коммутатор. Интерфейс Bridge представляет собой как сам виртуальный сетевой коммутатор, так и сетевой интерфейс с ip адресом, назначенным на порт этого коммутатора. Подключение должно быть выполнено по следующей схеме (рис. 3).

На labnode-1 требуется создать конфиг ifcfg-br0:
sudo vi /etc/sysconfig/network-scripts/ifcfg-br0
Мост будет иметь следующую конфигурацию:sudo
TYPE=Bridge
DEVICE=br0
BOOTPROTO=static
IPADDR=10.0.12.20
PREFIX=24
STP=on
ONBOOT=yes
Spanning Tree Protocol (STP) нужен, чтобы избежать петель коммутации.
Интерфейс bond0, настроенный до этого, может быть интерфейсом этого сетевого коммутатора,
но в таком случае ip адрес уже будет назначен на интерфейс виртуального сетевого коммутатора,
и все настройки ip с интерфейса bond0 можно будет убрать.
Для этого в конфигурационный файл интерфейса bond0 также нужно добавить параметр
BRIDGE=br0. Также удалить из него параметры BOOTPROTO, IPADDR, PREFIX, ONBOOT
(можно просто закомментировать с помощью символа #, когда пригодятся, раскомментировать
их, убрав символ #):
sudo vi /etc/sysconfig/network-scripts/ifcfg-bond0
Перезагрузить сеть:
sudo systemctl restart network
Можно проверить результат. Для этого на labnode-2 выполнить следующую команду:
ip address
Проверить, что в результате вывода этой команды ip адрес будет назначен только на интерфейс br0, и он будет в состоянии UP. Если все правильно, то проверить доступность соседнего узла командой:
ping -c 4 10.0.12.20
Мост может подняться не сразу. Необходимо подождать.
Задание 5. Создание VxLAN интерфейсов.
VxLAN является механизмом построения виртуальных сетей на основаниях тоннелей, поверх реальных сетей, но при этом позволяющим их разграничивать.
Подключение должно быть выполнено по следующей схеме (рис. 4).

На labnode-1 удалить конфигурацию моста br0:
sudo rm /etc/sysconfig/network-scripts/ifcfg-br0
И привести bond0 к прежнему виду:
TYPE=Bond
DEVICE=bond0
BOOTPROTO=static
IPADDR=10.0.12.20
PREFIX=24
#BRIDGE=br0
BONDING_MASTER=yes
BONDING_OPTS="mode=0 miimon=100"
ONBOOT=yes
И перезагрузить сервер:
sudo reboot
После загрузки сервера проверить работу сети с узла labnode-2:
ping -c 4 10.0.12.20
На labnode-1 добавить интерфейс vxlan10:
sudo ip link add vxlan10 type vxlan id 10 dstport 0 dev bond0
Настроить коммутацию Linux Bridge:
sudo bridge fdb append to 00:00:00:00:00:00 dst 10.0.12.30 dev vxlan10
Назначить vxlan10 IP адрес и перевести его в состояние up:
sudo ip addr add 192.168.1.20/24 dev vxlan10
sudo ip link set up dev vxlan10
VxLAN работает как приложение. Пакеты инкапсулируются в udp, и для работы VxLAN требуется udp порт 8472. Открыть его в фаерволе:
sudo firewall-cmd --permanent --add-port=8472/udp
sudo firewall-cmd --reload
После нужно сделать все то же самое на labnode-2. Добавить интерфейс vxlan10:
sudo ip link add vxlan10 type vxlan id 10 dstport 0 dev bond0
Настроить коммутацию Linux Bridge:
sudo bridge fdb append to 00:00:00:00:00:00 dst 10.0.12.20 dev vxlan10
Назначить vxlan10 IP адрес и перевести его в состояние up:
sudo ip addr add 192.168.1.30/24 dev vxlan10
sudo ip link set up dev vxlan10
Протестировать соединение через vxlan. Для этого на labnode-1:
ping -c 4 192.168.1.30
Посмотреть на arp таблицу. Там можно увидеть соответствие mac адресов с ip адресами.
arp
Нужно убедиться, что появилось приложение, которое слушает порт 8472.
ss -tulpn | grep 8472
Теперь необходимо добавить vxlan с другим тегом (20), и убедиться в том, что из него не будет доступа к vxlan с тегом 10 (пакеты будут отбрасываться из-за разных тегов). Перезагрузить labnode-2. Текущая настройка vxlan сбросится.
sudo reboot
На labnode-2 добавить интерфейс vxlan20 и настроить его:
sudo ip link add vxlan20 type vxlan id 20 dstport 0 dev bond0
sudo bridge fdb append to 00:00:00:00:00:00 dst 10.0.12.20 dev vxlan20
sudo ip addr add 192.168.1.30/24 dev vxlan20
sudo ip link set up dev vxlan20
ss -tulpn | grep 8472
Протестировать соединение через vxlan. Для этого на labnode-1:
ping 192.168.1.30 -c 4
Работа с сетевой подсистемой Linux. Часть 2
Схема виртуального лабораторного стенда
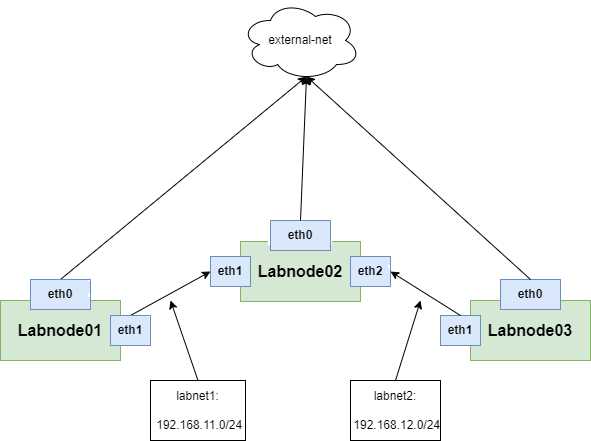
Задание 0. Построение стенда
1. Создать 2 виртуальные сети:
- labnet1
- labnet2
| Название сети/подсети | Сетевой адрес | mtu |
|---|---|---|
| labnet1 | 192.168.11.0/24 | 1492 |
| labnet2 | 192.168.12.0/24 | 1492 |
При создании подсети необходимо выбрать пункт "Запретить шлюз"
Пример создания сетей
Для создания сети нужно перейти в сети:
Создать порты для дальнейшего использования.
Пример создания порта
Cоздать порты:
2. Создать виртуальные машины для работы
Перед созданием виртуальной машины необходимо продумать схему ip адресации для взаимодействия между узлами:
- Для взаимодействия между узлами labnode01 и labnode02 необходимо выбрать адреса из сети 192.168.11.0/24
- Для взаимодействия между узлами labnode02 и labnode03 необходимо выбрать адреса из сети 192.168.12.0/24
| Название виртуальной машины | Источник | Тип инстанса | Сети для внешнего подключения |
|---|---|---|---|
| labnode01 | Образ-Ubuntu-server20.04 | small | external-net |
| labnode02 | Образ-Ubuntu-server20.04 | small | external-net |
| labnode03 | Образ-Ubuntu-server20.04 | small | external-net |
Так же нужно проверить развернутую инфраструктуру на соответствие схеме на рисунке 1.
Задание 1. Настройка маршрутизации
В данном задании на развернутом стенде нужно настроить статическую маршрутизацию на узле.
Для самостоятельной работы нужно выполнить следующее:
- настроить статические маршруты на узлах labnode01, labnode02 и labnode03
- Проверить доступность узла labnode03 с узла labnode01
- Зафиксировать результат проверки
Задание 2. Настройка трансляции адресов
Для самостоятельной работы нужно выполнить следующее:
- настроить статические маршруты на узлах labnode01 и labnode03
- С помощью iptables настроить трансляцию адресов на узле labnode02(вместо адреса источника должен подставляться адрес центрального шлюза)
- Проверить доступность узла labnode03 с узла labnode01
- С помощью утилиты tcpdump проверить, что при проверках связи между узлами labnode01 и labnode03 приходят пакеты, адрес источника в которых равен адресу шлюза
- Зафиксировать результат проверки tcpdump
Задание 3. Настройка DNS сервера на узле labnode-3
- Установить пакет Bind на сервере labnode03
- Установить утилиту dig на сервере labnode01
- Настроить на сервере Bind узла labnode03 DNS зону - example.com
- Настроить A запись для доменного имени labnode03.example.com, указывающего на ip адрес узла labnode03
- Прописать на узле labnode01 обращение к dns серверу labnode03.
- С помощью утилиты dig, обратившись к этому серверу проверить - что записи возвращаются корректно.
- ДОП: Включить логирование на сервере Bind и обнаружить в нем обращение к dns серверу с узла labnode01
Работа с DNS
Задачи
- Установить и настроить авторитетного DNS сервера
- Настроить DNS для работы в соответствии со стандартом RFC 2136
- Установка и настройка рекурсивного DNS
- Выпустить сертификат безопасности
- Проверить сертификата безопасности
Построение стенда
Схема виртуального лабораторного стенда

Рисунок 1. Схема стенда
- Создать виртуальные машины для работы
| Название виртуальной машины | Источник | Тип инстанса | Сети для внешнего подключения |
|---|---|---|---|
| web-server | Образ-Ubuntu-server20.04 | small | external-net |
| dns-server | Образ-Ubuntu-server20.04 | small | external-net |
Так же нужно проверить развернутую инфраструктуру на соответствие схеме на рисунке 1.
В группах безопастности необходимо разрешить DNS
1. Установка и настройка авторитетного DNS сервера
Обновляем пакеты внутри системы до последней версии
sudo apt update
# Необязательно, но желательно
sudo apt full-upgrade -y
Устанавливаем сервер реализацию DNS сервера PowerDNS
sudo apt install pdns-server pdns-backend-sqlite3 sqlite3 -y
Настроить для работы c sqlite бд
sudo mkdir /var/lib/powerdns
sudo sqlite3 /var/lib/powerdns/pdns.sqlite3 < /usr/share/doc/pdns-backend-sqlite3/schema.sqlite3.sql
sudo chown -R pdns:pdns /var/lib/powerdns
Выключаем systemd-resolved
sudo systemctl disable --now systemd-resolved.service
Изменяем используемый dns-сервер на 172.17.1.10
sudo rm -rf /etc/resolv.conf
echo "nameserver 172.17.1.10" |sudo tee /etc/resolv.conf
Отредактировать /etc/powerdns/pdns.conf
include-dir=/etc/powerdns/pdns.d
launch=gsqlite3
gsqlite3-database=/var/lib/powerdns/pdns.sqlite3
security-poll-suffix=
setgid=pdns
setuid=pdns
- include-dir=/etc/powerdns/pdns.d: Эта строка указывает серверу PowerDNS загружать все конфигурационные файлы из директории /etc/powerdns/pdns.d. Это позволяет разделять конфигурацию на несколько файлов для более удобного управления.
- launch=gsqlite3: Эта строка определяет, какой бэкенд базы данных будет использоваться для хранения данных сервера DNS. В данном случае, указан бэкенд gsqlite3, что означает использование базы данных SQLite.
- gsqlite3-database=/var/lib/powerdns/pdns.sqlite3: Здесь указывается путь к файлу базы данных SQLite, который будет использоваться сервером PowerDNS для хранения записей DNS.
- security-poll-suffix=: Этот параметр связан с безопасностью и суффиксом для защиты от определенных видов атак. В данном случае, он не задан (пустое значение), в данном случае это означает не использовать варианты защиты.
- setgid=pdns и setuid=pdns: Эти параметры устанавливают идентификатор группы и пользователя, от которого будет работать процесс PowerDNS. В этом случае, сервер будет запущен с правами группы pdns и пользователем pdns для обеспечения минимальных привилегий в целях безопасности.
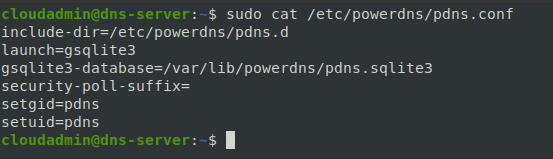
Рисунок 2. Пример конфига
Активируем демона dns-сервера
sudo systemctl enable --now pdns
Создаем зону по имени пользователя(для примера используется devops-course.test)
sudo pdnsutil create-zone {zone name} ns1.{zone name}
sudo pdnsutil add-record {zone name}. www A 127.0.0.1

Проверьте работу сервера
nslookup www.devops-course.test {server ip}
Запрос делается с пользователького пк
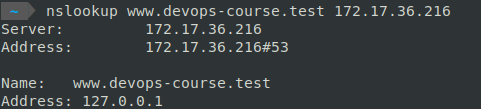
Рисунок 3. Пример ответ при адресе сервера 172.17.36.216
2. Настроить DNS для работы в соответствии со стандартом RFC 2136
Для работы по стандарту rfc2136, необходимо изменить конфигурацию работы PowerDNS, в конфигурационном файле необходимо добавить строки:
dnsupdate=yes
allow-dnsupdate-from=172.16.0.0/12
- dnsupdate=yes - это включает поддержку динамического обновления DNS-записей (DNSUPDATE), что позволяет клиентам обновлять записи на сервере DNS.
- allow-dnsupdate-from=172.16.0.0/12 - это определяет диапазон IP-адресов (в данном случае, подсеть) для разрешения выполнения динамических обновлений DNS. Только запросы, идущие от адресов в этой подсети (172.16.0.0 - 172.31.255.255), будут разрешены для выполнения обновлений.
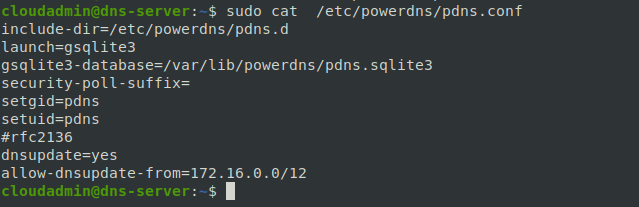
Рисунок 4. Конфигурация после обновления
Создать TSIG ключ с именем dnsudpater
sudo pdnsutil generate-tsig-key dnsupdater hmac-sha512
pdnsutil - это утилита для работы с PowerDNS. generate-tsig-key - команда для создания нового ключа TSIG. dnsupdater - это имя, которое будет присвоено сгенерированному ключу TSIG. hmac-sha512 - это алгоритм хеширования, используемый для создания ключа.

Рисунок 5. Пример корректного создания TSIG ключа
Посмотреть существующие ключи можно командой:
sudo pdnsutil list-tsig-keys
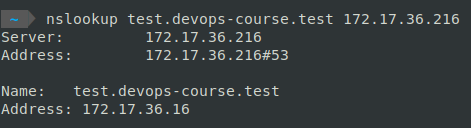
Для проверки работы rfc2136 добавим новую A запись test указывающую, на наш web-сервер
nsupdate <<!
server {ip dns-server} 53
zone {zone name}
update add test.{zone name} 3600 A {ip web-server}
key hmac-sha512:{key name} {tsig key}
send
!
выполнять с устройства в сети 172.16.0.0/12

Проверить, что запись добавилась
nslookup test.{zone name} {ip dns-server}
3. Настройка рекурсивного DNS
Так как наша конфигурация подразумевает совместную работы рекурсивного и авторитетного сервера на одном виртуальном сервере, нам необходимо разграничить их по портам, так для авторитетного сервера, будет использовать порт 5353
Для этого в конфигурации авторитетного сервера необходимо изменить слушаемые порт добавив в конфигурационный файл строки
local-port=5353
После изменения конфигурации необходимо перезапустить службу
sudo systemctl restart pdns
Проверьте, что теперь слушается только порт 5353
ss -tulpan
Установите рекурсивный сервер DNS
sudo apt install pdns-recursor -y
Привести конфиг(/etc/powerdns/recursor.conf) рекурсивного DNS к виду:
config-dir=/etc/powerdns
hint-file=/usr/share/dns/root.hints
include-dir=/etc/powerdns/recursor.d
local-address=0.0.0.0
local-port=53
lua-config-file=/etc/powerdns/recursor.lua
public-suffix-list-file=/usr/share/publicsuffix/public_suffix_list.dat
quiet=yes
security-poll-suffix=
setgid=pdns
setuid=pdns
# authoritative zone
forward-zones={zone name}=127.0.0.1:5353
forward-zones-recurse={zone name}=127.0.0.1:5353
# also
forward-zones+=.=1.1.1.1
forward-zones-recurse+=.=1.1.1.1
- config-dir=/etc/powerdns - указывает на папку с дополнительными файлами конфигурации для PowerDNS Recursor.
- hint-file=/usr/share/dns/root.hints - определяет местоположение файла с базовыми подсказками (hints) для поиска корневых серверов DNS.
- include-dir=/etc/powerdns/recursor.d - указывает на папку, где Recursor будет искать дополнительные файлы конфигурации для обработки.
- local-address=0.0.0.0 и local-port=53 - определяют, на каком адресе и порту будет слушать Recursor для входящих DNS-запросов.
- lua-config-file=/etc/powerdns/recursor.lua - указывает на файл конфигурации Lua, который может содержать дополнительные пользовательские настройки для Recursor.
- quiet=yes - включает режим тишины, что означает меньше вывода информации в логах или на консоль.
- forward-zones={zone name}=127.0.0.1:5353 и forward-zones-recurse={zone name}=127.0.0.1:5353 - эти строки настраивают перенаправление запросов для конкретной зоны {zone name} на адрес 127.0.0.1 с портом 5353.
- forward-zones+=.=1.1.1.1 и forward-zones-recurse+=.=1.1.1.1 - эти строки добавляют общее перенаправление запросов для всех неопределенныз явным образом зон на указанный IP-адрес (1.1.1.1).
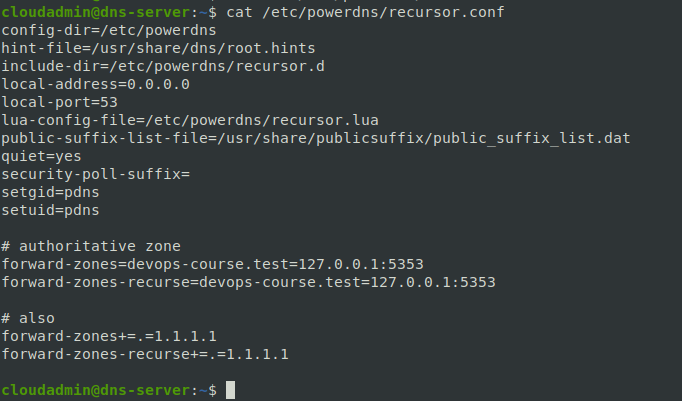
Включаем и добавляем автозапуск демона
sudo systemctl enable pdns-recursor
sudo systemctl restart pdns-recursor
4. Выпуск сертификата безопасности
Переходим на узел веб сервера и используя команду генерируем самоподписанный сертификат для нашего будущего тестового сайта
openssl req -x509 -nodes -newkey rsa:4096 -keyout key.pem -out cert.pem -days 365 -subj '/CN={Доменное имя}' -addext "subjectAltName = DNS:{Доменное имя}" -addext "keyUsage = digitalSignature, keyEncipherment" -addext "extendedKeyUsage = serverAuth"
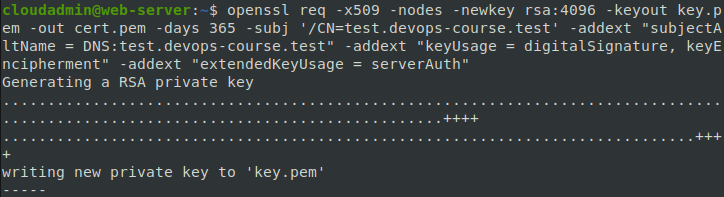
Пример создания сертификата
Для проверки созданного сертификата можно использовать команду
openssl x509 -in cert.pem -noout -text
5. Проверка сертификата безопасности
Для проверки мы установим nginx и установим на него ранее созданный сертификат. Нам необходимо начать с установки nginx
sudo apt update
sudo apt install nginx -y
После установки необходимо конфигурацию по умолчанию(/etc/nginx/sites-available/default) и привести ее к виду:
server {
listen 80 default_server;
server_name {доменное имя};
return 301 https://$host$request_uri;
}
server {
listen 443 ssl http2;
server_name {доменное имя};
ssl_certificate /home/cloudadmin/cert.pem;
ssl_certificate_key /home/cloudadmin/key.pem;
ssl_session_cache builtin:1000 shared:SSL:10m;
ssl_protocols TLSv1.3;
ssl_ciphers HIGH:!aNULL:!eNULL:!EXPORT:!CAMELLIA:!DES:!MD5:!PSK:!RC4;
ssl_prefer_server_ciphers on;
access_log /var/log/nginx/cloud.access.log;
error_log /var/log/nginx/cloud.error.log;
root /var/www/html;
index index.html index.htm index.nginx-debian.html;
location / {
try_files $uri $uri/ =404;
}
}
После этого можно проверить конфигурацию nginx и перезапустить демона
sudo nginx -t
sudo systemctl restart nginx

Пример ответа при правильной конфигурации
После этого необходимо убедиться в наличии созданного вами доменного имени с помощью утилиты dig
dig {доменное имя} @{адрес dns сервера}
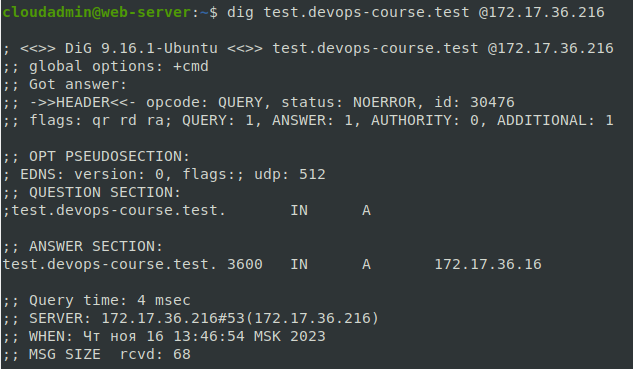
Пример валидного ответа
После этого Вам необходимо изменить DNS сервер на вашем устройстве, на созданный вами DNS сервер и попробовать открыть в браузере ваш домен
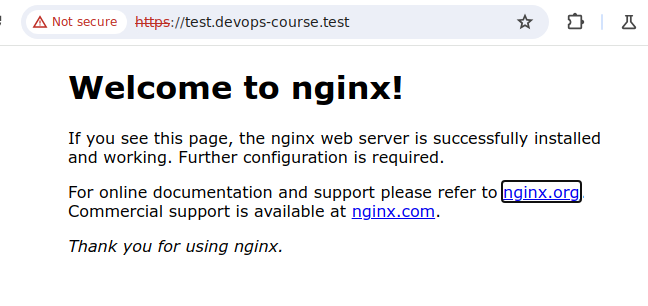
Пример выполненой работы
Работа с дисковой подсистемой Linux
Задание 0. Построение стенда
Схема виртуального лабораторного стенда

Рисунок 1. Схема стенда
- Создать виртуальные машины для работы
| Название виртуальной машины | Источник | Тип инстанса | Сети для внешнего подключения |
|---|---|---|---|
| Test-server | Образ-Ubuntu-server20.04 | small | external-net |
Диск VDA создается при создании VM
Диск VDB 8GB
Так же нужно проверить развернутую инфраструктуру на соответствие схеме на рисунке 1.
Задание 1. Создание разделов с использованием fdisk на MBR.
Необходимо сделать на диске следующую разметку:

Для этого запустить fdisk в интерактивном режиме, в качестве аргумента передавая путь к блочному устройству.
sudo fdisk /dev/vdb
- Создать разметку DOS (MBR), с помощью команды
o. - Создать primary раздел. Нажать
n, для создания нового раздела. Нажатьp, указывая, что нужен именно primary. Номер раздела выбрать -1(можно ничего не выбирать, так как этот номер раздела используется по умолчанию). Утилита fdisk автоматически рассчитывает свободный сектор, с которого можно начать создание раздела. Для первого сектора первого раздела это будет сектор 2048 (можно ничего не выбирать, а просто нажатьenterтак как этот номер раздела используется по умолчанию. Для всех последующих разделовfdiskбудет сам вычислять первый незанятый сектор, и предлагать его по умолчанию). При указании последнего сектора необходимо указать+1G(утилитаfdiskавтоматически рассчитает нужное количество секторов). В итоге должен получиться primary раздел на 1 ГБ. Проверить, что раздел добавлен в таблицу разделов, с помощью командыp. - Создать ещё один раздел на 5 ГБ, но с типом extended. Сделать всё то же самое как в пункте 2, но выбрать вместо primary, extended, набрав
e, и последний сектор указать+5Gот первого рекомендуемого. - Создать два логических раздела по 1 ГБ и один на 2 ГБ (логические тома могут быть созданы только при наличии extended раздела, и размещаются “внутри” extended раздела). Для этого выбрать тип раздела - logical, нажав
l. - Создать еще один primary раздел на 1 ГБ.
- Проверить получившуюся таблицу разделов, с помощью
p. Если всё было сделано правильно, должен получиться следующий результат:
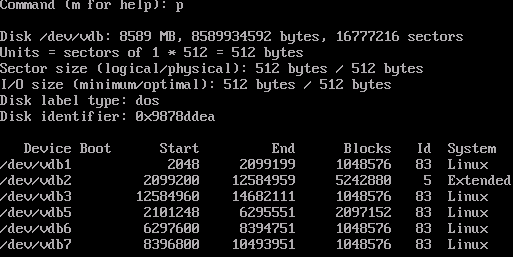
- После этого, необходимо записать эту таблицу на диск, нажав w. После выполнения этой команда утилита fdisk завершит работу и вернет вас в оболочку пользователя.
Проверить, что все изменения применились можно с помощью следующей команды:
lsblk
В результате на диске vdb должно отображаться 6 новых разделов.
Задание 2. Создание файловой системы.
Создать файловые системы на разделах, созданных в предыдущем задании. Пусть:
- На vdb1 ext4.
- На vdb3 - xfs.
- На vdb5 - btrfs.
Делается это так:
sudo mkfs.ext4 /dev/vdb1
sudo mkfs.xfs /dev/vdb3
sudo mkfs.btrfs /dev/vdb5
Проверить, что файловые системы были созданы.
sudo lsblk -f
Теперь, в каталоге пользователя, создать каталог media.
mkdir ~/media
Примонтировать раздел.
sudo mount /dev/vdb5 /home/labuser/media/
После этого можно размещать файлы в каталоге /home/labuser/media/ и они будут размещаться на диске vdb. Проверить куда и какие разделы примонтированы можно с помощью команды sudo mount без аргументов.
Для выполнения дальнейших этапов работы необходимо отмонтировать данный раздел:
sudo umount /dev/vdb5
Задание 3. Создание разделов с использованием fdisk на GPT.
Запустить fdisk в интерактивном режиме, в качестве аргумента передавая путь к блочному устройству.
sudo fdisk /dev/vdb
- Выбрать таблицу разметки GPT. Делается это, нажав
g. - Создать 3 раздела, согласно схеме. Сделать это с помощью команды
n, как и в случае с MBR.

Задание 4. Работа с LVM.
В этом задании используется разметка из задания 3. Для выполнения этого задания потребуется пакет lvm2. Установить его можно с помощью yum.
sudo apt install lvm2
Сначала необходимо изменить системный id раздела. Он влияет на то, какая метка файловой системы будет отображаться в fdisk в столбце Type.
Запустить fdisk в интерактивном режиме, в качестве аргумента передавая путь к блочному устройству.
sudo fdisk /dev/vdb
- Необходимо изменить тип раздела всем разделам. Нажав t, выбрать номер раздела, метку которого нужно поменять. Далее необходимо нажать L, чтобы просмотреть все доступные метки. Нужно найти Linux LVM (поиск в текстовой консоли может быть затруднен из-за длинного списка. Пролистать список вверх можно с помощью клавиш shift + PgUp, либо просто ввести значение метки - 31). Набрать id, под которым стоит нужная метка.
- Проделать эту операцию со всеми разделами на диске.
- Необходимо проверить введенные значения, а после записать их, нажав w.
- Необходимо сделать все три раздела физическими томами (В процессе будет сообщение, что файловая система на томе будет уничтожена. Нужно согласиться, набрав
y).
sudo pvcreate /dev/vdb1
sudo pvcreate /dev/vdb2
sudo pvcreate /dev/vdb3
Проверить успешность можно с помощью команды sudo pvdisplay. Эта команда должна вывести список всех PV(физических устройств), на которых могут быть размещены тома LVM.
- На этих физических томах создать группу томов, и задать ей имя. Имя можно выбрать любое, например vg1:
sudo vgcreate vg1 /dev/vdb1 /dev/vdb2 /dev/vdb3
Проверить с помощью sudo vgdisplay. В результате должна отобразиться 1 VG (группа томов), в данном случае vg1.
6. Теперь в группе томов можно создать логические тома lv1 и lv2 размером 1 ГБ и 2 ГБ соответственно.
sudo lvcreate -n lv1 -L 1G vg1
sudo lvcreate -n lv2 -L 2G vg1
Проверить с помощью sudo lvdisplay. В результате должны отобразиться 2 LV (логических тома) lv1 и lv2.
- Теперь в системе появились блочные устройства /dev/vg1/lv1 и /dev/vg1/lv2. Осталось создать на них файловую систему. Тут различий с обычными разделами нет.
sudo mkfs.ext4 /dev/vg1/lv1
sudo mkfs.ext4 /dev/vg1/lv2
- Удаление физических томов. Удалить из группы том /dev/vdb1. Чтобы убрать из работающей группы томов раздел, сначала необходимо перенести все данные с него на другие разделы:
sudo pvmove /dev/vdb1
Затем удалить его из группы томов:
sudo vgreduce vg1 /dev/vdb1
И, наконец, удалить физический том:
sudo pvremove /dev/vdb1
Последняя команда просто убирает отметку о том, что диск является членом lvm, и не удаляет ни данные на разделе, ни сам раздел. После удаления физического тома из LVM для дальнейшего использования диск придётся переразбивать/переформатировать.
- Добавление физических томов. Необходимо расширить VG, добавив к нему том /dev/vdb1. Чтобы добавить новый том в группу томов, создать физический том:
sudo pvcreate /dev/vdb1
Добавить его в группу:
sudo vgextend vg1 /dev/vdb1
Теперь можно создать ещё один логический диск (lvcreate) или увеличить размер существующего (lvresize).
- Изменение размеров LVM позволяет легко изменять размер логических томов. Для этого нужно сначала изменить сам логический том:
sudo lvresize -L 3G vg1/lv2
Так как логический том является обычным дисковым (блочным) устройством, расширение этого дискового устройство никак не скажется на файловой системе, находящейся на нем, и не приведет к увеличению ее размера. Чтобы файловая система заняла все свободное место на блочном устройстве, необходимо её расширить отдельной командой: А затем файловую систему на нём:
sudo resize2fs /dev/vg1/lv2
Задание 5. Монтирование разделов.
Удалить существующие логические LVM разделы, и создать новый.
sudo lvremove /dev/vg1/lv1
sudo lvremove /dev/vg1/lv2
sudo lvcreate -n media -L 6G vg1
sudo mkfs.ext4 /dev/vg1/media
Далее необходимо примонтировать раздел.
sudo mount /dev/vg1/media /home/labuser/media/
Записать тестовый файл test.
echo "string" | sudo tee ~/media/test
Если проблемы с доступом к записи, сменить владельца каталога. После выполнить команду заново.
sudo chown labuser:labuser /home/labuser/media/*
Отмонтировать раздел.
sudo umount /home/labuser/media/
Зайти внутрь созданного каталога, и удостовериться, что файла test там нет. Он остался на разделе. Чтобы после перезагрузки не монтировать раздел заново, нужно добавить автомонтирование в конфигурационный файл /etc/fstab (удалять из этого файла ничего нельзя! В случае ошибки в конфигурационном файле операционная система не загрузится, делать очень внимательно!). Для начало необходимо сохранить резервную копию конфигурационного файла:
sudo cp /etc/fstab /etc/fstab.old
Далее необходимо открыть его, чтобы изменить содержимое:
sudo vi /etc/fstab
Добавить туда следующую строку и сохранить.
/dev/vg1/media /home/labuser/media ext4 defaults 0 0
Для того чтобы убедиться в корректности сохранения, необходимо вывести в консоль содержимое файла /etc/fstab командой:
sudo cat /etc/fstab
Необходимо проверить, что изначальное содержимое файла сохранено, и так же в нём есть добавленная запись. Если содержимое отличается от ожидаемого, то необходимо восстановить сохраненную версию, и произвести все изменения ещё раз. После этого повторить проверку. Восстановить содержимое можно следующей командой:
sudo cp /etc/fstab.old /etc/fstab
Перезагрузить систему с помощью команды reboot. После загрузки зайти в каталог ~/media, требуется увидеть файл test.
Задание 6. Самостоятельная работа
- Создать и добавить диск на
4gb. - Разметить на диске
5разделов по513mb - Создать файловые системы на разделах:
ext2,ext4,xfs,btrfs,ntfs. - В директории /opt создать, 5 директорий(по названию фс) и смонтировать туда разделы
- Добавить автоматическое монтирование новых разделов
Настройка сетевого хранилища
Задание 0. Построение стенда
Схема виртуального лабораторного стенда

Рисунок 1. Схема стенда
1. Создать 2 виртуальные сети:
- labnet1
- labnet2
| Название сети/подсети | Сетевой адрес | mtu |
|---|---|---|
| labnet1 | 192.168.11.0/24 | 1481 |
| labnet2 | 192.168.12.0/24 | 1481 |
При создании подсети необходимо выбрать пункт "Запретить шлюз"
2. Создать виртуальные машины для работы
| Название виртуальной машины | Источник | Тип инстанса | Сети для внешнего подключения | Размер диска | Размер доп диска |
|---|---|---|---|---|---|
| nfs-client | Образ-Ubuntu-server20.04 | small | external-net | 10GB | 2gb |
| router | Образ-Ubuntu-server20.04 | small | external-net | 10GB | 2gb |
| nfs-server | Образ-Ubuntu-server20.04 | small | external-net | 10GB | 2gb |
Перед созданием виртуальной машины необходимо продумать схему ip адресации для взаимодействия между узлами:
- Для взаимодействия между узлами nfs-server и router необходимо выбрать адреса из сети 192.168.11.0/24
- Для взаимодействия между узлами router и nfs-client необходимо выбрать адреса из сети 192.168.12.0/24
Задание 1. Настройка маршрутизации
В данном задании на развернутом стенде нужно настроить маршрутизацию между узлами сети.
Для самостоятельной работы нужно выполнить следующее:
- Проверить доступность узла nfs-server с узла nfs-client
- Проверить доступность узла nfs-client с узла nfs-server
- Зафиксировать результат проверки
Задание 2. Настройка NFS
Для самостоятельной работы нужно выполнить следующее:
- Установить NFS на nfs-server
- Создать каталог для экспорта на дополнительном диске
- Настроить доступ к директории
Задание 3. Настройка доступа к хранилищу
- На nfs-client создать директорию для монтирования
- Смонтировать в директории NFS хранилище
Взаимодействие через
labnet1,labnet2 - Создать в директории текстовый файл с названием проекта
- Добавить в авто монтирование хранилище на узлах
- Перезагрузить узел nfs-client и проверить наличие доступа после загрузки системы
- Выключить nfs-server, перезагрузить nfs-client и проверить включение
Работа с виртуализацией: QEMU/KVM. Часть 1
Задание 0. Построение стенда
Схема виртуального лабораторного стенда

Рисунок 1. Схема стенда
- Создать виртуальные машины для работы
| Название виртуальной машины | Источник | Тип инстанса | Сети для внешнего подключения | Размер диска |
|---|---|---|---|---|
| labnode-1 | Образ-Ubuntu-server20.04 | small | external-net | 10GB |
Так же нужно проверить развернутую инфраструктуру на соответствие схеме на рисунке 1.
Задание 1. Установка QEMU.
На labnode-1:
- Установить эмулятор аппаратного обеспечения различных платформ:
sudo apt update
sudo apt install qemu-kvm qemu-system qemu-utils -y
- Убедиться, что модуль KVM загружен (с помощью команд lsmod и grep):
lsmod | grep -i kvm

Задание 2. Управление образами дисков при помощи qemu-img.
Чтобы запускать виртуальные машины, QEMU требуются образы для хранения определенной файловой системы данной гостевой ОС. Такой образ сам по себе имеет тип некоторого файла, и он представляет всю гостевую файловую систему, расположенную в некотором виртуальном диске. QEMU поддерживает различные образы и предоставляет инструменты для создания и управления ими. Можно построить пустой образ диска с помощью утилиты qemu-img, которая должна быть установлена.
- Проверить какие типы образов поддерживаются qemu-img:
sudo qemu-img -h | grep Supported
- Создать образ qcow2 с названием system.qcow2 и размером 5 ГБ:
sudo qemu-img create -f qcow2 system.qcow2 5G
- Проверить что файл был создан:
ls -lah system.qcow2
- Посмотреть дополнительную информацию о данном образе:
sudo qemu-img info system.qcow2
Задание 3. Изменение размера образа.
Не все типы образов поддерживают изменение размера. Для изменения размера такого образа сначала нужно преобразовать его в образ raw с помощью команды qemu-img convert.
- Конвертировать образ диска из формата qcow2 в raw:
sudo qemu-img convert -f qcow2 -O raw system.qcow2 system.raw
- Добавить дополнительно 5 ГБ к образу:
sudo qemu-img resize -f raw system.raw +5G
- Проверить новый текущий размер образа:
sudo qemu-img info system.raw
- Конвертировать образ диска обратно из raw в qcow2:
sudo qemu-img convert -f raw -O qcow2 system.raw system.qcow2
Задание 4. Загрузка образа OpenWRT.
Для загрузки образов с общедоступных репозиториев требуется утилита curl. Загрузить необходимый образ, воспользовавшись curl:
curl -L https://s3.resds.ru/itt/openwrt.img -o /tmp/openwrt.raw
Задание 5. Создание виртуального окружения с помощью qemu-system.
- Для того чтобы подключиться к виртуальной машине по протоколу удаленного рабочего стола VNC, нужно открыть порт 5900. В группе безопасности
- Посмотреть ip адрес вашего сервера
ip address
- Запустить систему при помощи qemu-system:
sudo qemu-system-x86_64 -hda /tmp/openwrt.raw -m 1024 -vga cirrus -vnc 0.0.0.0:0
-
Установите и откройте программу (Remmina). И подключитесь по протоколу
VNCк гипервизору -
Набрать команду uname -a. Посмотреть на версию ядра ОС. Выключить виртуальную машину, набрав
poweroff
Задание 6. Установка Libvirt и Virsh.
sudo apt install -y libvirt-daemon-system virtinst
Задание 7. Настройка моста.
Установить пакет bridge-utils:
sudo apt install -y bridge-utils
Вывести на экран имеющиеся интерфейсы:
ip -c address
Открыть файл /tmp/labnet.xml:
sudo vi /tmp/labnet.xml
И заполнить по примеру
<network>
<name>labnet</name>
<forward mode='nat'>
<nat>
<port start='1024' end='65535'/>
</nat>
</forward>
<bridge name='labnet' stp='on' delay='0'/>
<ip address='192.168.22.1' netmask='255.255.255.0'>
<dhcp>
<range start='192.168.22.2' end='192.168.22.254'/>
</dhcp>
</ip>
</network>
Добавляем сеть и запускаем ее:
sudo virsh net-define /tmp/labnet.xml
sudo virsh net-start labnet
sudo virsh net-autostart labnet
Задание 8. Создание виртуальной машины.
Переместить образ openwrt в /var/lib/libvirt/images/
sudo mv /tmp/openwrt.raw /var/lib/libvirt/images/
Следующая команда создаст новую KVM виртуальную машину
sudo virt-install --name openwrt \
--ram 1024 \
--disk path=/var/lib/libvirt/images/openwrt.raw,cache=none \
--boot hd \
--vcpus 1 \
--network network=labnet \
--graphics vnc,listen=0.0.0.0 \
--wait 0
Символ \ - обратная косая черта используется для экранирования специальных символов в строковых и символьных литералах. В данном случае нужна, чтобы переместить каретку на новую строку, для наглядности. После ее добавления в команду можно нажать Enter, но строка не отправится на выполнение, а ввод команды продолжится. При ошибке в наборе команды, можно не набирать ее заново, а нажать стрелку вверх, исправить ее, и снова нажать Enter
Подробнее о параметрах:
| Название параметра | Описание параметра |
|---|---|
| name | Имя виртуальной машины, которое будет отображаться в virsh |
| ram | Размер оперативной памяти в МБ |
| disk | Диск, который будет создан и подключен к виртуальной машине |
| vcpus | Количество виртуальных процессоров, которые нужно будет настроить для гостя |
| os-type | Тип операционной системы |
| os-variant | Название операционной системы |
| network | Определение сетевого интерфейса, который будет подключен к виртуальной машине |
| graphics | Определяет графическую конфигурацию дисплея. |
| cdrom | CD ROM устройство |
Далее необходимо подключиться к гипервизору через программу Remmina.
Открыть её (название - Remmina). Подключиться по адресу виртуальной машины, выбрав протокол VNC.Вернуться в консоль labnode-1. Проверить состояние гостевой системы, используя команду
(Если в консоли написано “Domain installation still in progress”, то нажмите ^C):
sudo virsh list --all
Задание 9. Операции с виртуальной машиной.

Рассмотрим работу утилиты virsh. Чтобы подключиться к ВМ по протоколу удаленного доступа, используется следующая команда:
sudo virsh domdisplay openwrt
Результатом исполнения этой команды будет адрес для подключения к графическому интерфейсу ВМ, с указанием номера порта. Получить информацию о конкретной ВМ можно так:
sudo virsh dominfo openwrt
В результате чего будет выведена информация, об основных параметрах виртуальной машины. Выключить/включить ВМ можно с помощью команды:
sudo virsh destroy openwrt
sudo virsh start openwrt
Зайти в консоль виртуальной машины можно с помощью команды:
sudo virsh console openwrt
Посмотрите размер разделов
df -h
Выйдите из виртуальной машины
Добавление ВМ в автозапуск происходит следующим образом:
sudo virsh autostart openwrt
Теперь, виртуальная машина будет автоматически запускаться, после перезагрузки сервера. Кроме того, может потребоваться отредактировать XML конфигурацию ВМ:
sudo virsh edit openwrt
Необходимо выгрузить конфигурацию ВМ в XML в файл, используя команду:
sudo virsh dumpxml openwrt | tee openwrt.xml
Необходимо удалить ВМ, и убедиться, что её нет в списке виртуальных машин:
sudo virsh undefine openwrt
sudo virsh destroy openwrt
sudo virsh list --all
Увеличиваем размер диска на 1GB
sudo qemu-img resize -f raw /var/lib/libvirt/images/openwrt.raw +1G
Для создания ВМ из XML существует следующая команда:
sudo virsh define openwrt.xml
sudo virsh list --all
После запуска виртуальной машины необходимо увеличить размер основного раздела с помощью fdisk:
fdisk /dev/sda
После этого необходимо увеличить размер файловой системы:
BOOT="$(sed -n -e "/\s\/boot\s.*$/{s///p;q}" /etc/mtab)"
DISK="${BOOT%%[0-9]*}"
PART="$((${BOOT##*[^0-9]}+1))"
ROOT="${DISK}${PART}"
LOOP="$(losetup -f)"
losetup ${LOOP} ${ROOT}
fsck.ext4 -y -f ${LOOP}
resize2fs ${LOOP}
reboot
Проверить размер разделов
df -h
Работа с виртуализацией: QEMU/KVM. Часть 2
Задание 0. Построение стенда
Схема виртуального лабораторного стенда

Рисунок 1. Схема стенда
1. Создать 2 виртуальные сети:
- labnet-1
- labnet-2
| Название сети/подсети | Сетевой адрес | mtu |
|---|---|---|
| labnet-1 | 100.64.11.0/24 | 1481 |
| labnet-2 | 169.254.12.0/24 | 1481 |
При создании подсети необходимо выбрать пункт "Запретить шлюз"
2. Создать виртуальные машины для работы
| Название виртуальной машины | Источник | Тип инстанса | Сети для внешнего подключения | Размер диска | Размер доп диска |
|---|---|---|---|---|---|
| Labnode-1 | Образ-Ubuntu-server20.04 | small | external-net | 10GB | 7gb |
| Labnode-2 | Образ-Ubuntu-server20.04 | small | external-net | 10GB | - |
| Labnode-3 | Образ-Ubuntu-server20.04 | small | external-net | 10GB | - |
Перед созданием виртуальной машины необходимо продумать схему ip адресации для взаимодействия между узлами:
- Для взаимодействия между узлами Labnode-1 и Labnode-2 необходимо выбрать адреса из сети 100.64.11.0/24
- Для взаимодействия между узлами Labnode-2 и Labnode-3 необходимо выбрать адреса из сети 169.254.12.0/24
Задание 1. Настройка маршрутизации
В данном задании на развернутом стенде нужно настроить маршрутизацию между узлами сети.
Для самостоятельной работы нужно выполнить следующее:
- Проверить доступность узла labnode-1 с узла labnode-3
- Проверить доступность узла labnode-3 с узла labnode-1
- Зафиксировать результат проверки
Задание 2. Настройка NFS
Для самостоятельной работы нужно выполнить следующее:
- Установить NFS сервер на Labnode-1
- Создать каталог для экспорта на дополнительном диске
- Настроить доступ к директории
Задание 3. Настройка доступа к хранилищу
- На узлах создать директории для монтирования
- Смонтировать в директории NFS хранилище
Взаимодействие через
labnet-1,labnet-2 - Создать в директории текстовый файл с названием проекта
- Добавить в авто монтирование хранилище на узлах
Задание 4. Создать VM
- Скачайте образ OpenWRT
- Разместите образ системы в общей директории
- Создать VM на labnode-3
- Проверить возможность миграции VM на labnode-1
Построение кластера
Задание 0. Построение стенда
Схема виртуального лабораторного стенда

Рисунок 1. Схема стенда
1. Создать виртуальную сеть:
- labnet
| Название сети/подсети | Сетевой адрес | mtu |
|---|---|---|
| labnet | 10.0.12.0/24 | 1481 |
При создании подсети необходимо выбрать пункт "Запретить шлюз"
2. Создать виртуальные машины для работы
| Название виртуальной машины | Источник | Тип инстанса | Сети для внешнего подключения | Размер диска | Размер доп диска | ip в сети labnet |
|---|---|---|---|---|---|---|
| Labnode-1 | Образ-Ubuntu-server20.04 | small | external-net | 15GB | 75gb | 10.0.12.21 |
| Labnode-2 | Образ-Ubuntu-server20.04 | small | external-net | 15GB | - | 10.0.12.22 |
| Labnode-3 | Образ-Ubuntu-server20.04 | small | external-net | 15GB | - | 10.0.12.23 |
Задание 1. Настройка NFS
На labnode-1 необходимо настроить NFS сервер и использовать его на всех vm с точкой монтирования nfs /media/nfs_share/
Обратите внимание на fstab на узле labnode-1
Задание 2. Установка Pacemaker и Corosync
Установка очень проста. На всех узлах нужно выполнить команду:
sudo apt install -y pacemaker corosync pcs resource-agents qemu-kvm qemu-system qemu-utils qemu-kvm virt-manager libvirt-daemon-system virtinst libvirt-clients bridge-utils
Далее поднять pcs. Тоже, на всех узлах:
sudo systemctl start pcsd
sudo systemctl enable pcsd
Для обращения к узлам по имени, а не по адресу удобнее прописать на всех узлах сопоставление ip адреса и его имени. В таком случае, для сетевого взаимодействия между узлами можно будет обращаться по его имени. Для того чтобы прописать это соответствие, необходимо открыть файл /etc/hosts:
sudo vi /etc/hosts
Прописать в нем следующее:
10.0.12.21 labnode-1 labnode-1.novalocal
10.0.12.22 labnode-2 labnode-2.novalocal
10.0.12.23 labnode-3 labnode-3.novalocal
Задайте пользователю hacluster пароль на всех узлах(сам пользователь был автоматически создан в процессе установки pacemaker).
echo password | sudo passwd --stdin hacluster
И, с помощью pcs создать кластер (на одном из узлов):
sudo pcs cluster auth labnode-1 labnode-2 labnode-3 -u hacluster -p password --force
sudo pcs cluster setup --force --name labcluster labnode-1 labnode-2 labnode-3
sudo pcs cluster start --all
Отключить fencing (в рамках работы он не рассматривается)
sudo pcs property set stonith-enabled=false
Включить автозапуск сервисов на всех трех машинах:
sudo systemctl enable pacemaker corosync --now
sudo systemctl status pacemaker corosync
Просмотреть информацию о кластере и кворуме:
sudo pcs status
sudo corosync-quorumtool
Задание 3. Настройка моста.
На labnode-1, labnode-2 и labnode-3. Необходимо создать bridge интерфейсы c названием br0
без NAT
Задание 4. Создание ресурса
Необходимо создать VM на labnode-1 и разместить ее на общем nfs хранилище.
Для создания VM, необходимо использовать образ ubuntu22.04 и бридж br0
Его можно получить с s3:
curl -L https://s3.resds.ru/itt/ubuntu22.04.iso -o /tmp/ubuntu22.04.iso
После этого сделать дамп конфигурации VM и сохранить с названием ubuntu.xml
должны быть подключены к br0
все vm должны оказаться в одном l2 домене
Скопировать ubuntu.xml с labnode-1 на labnode-2 и labnode-3:
scp ubuntu.xml labnode-2:~
scp ubuntu.xml labnode-3:~
На labnode-1, labnode-2 и labnode-3 также переместить файл в /etc/pacemaker/
sudo mv ubuntu.xml /etc/pacemaker/
sudo chown hacluster:haclient /etc/pacemaker/ubuntu.xml
Теперь добавить сам ресурс:
sudo pcs resource create ubuntu VirtualDomain \
сonfig="/etc/pacemaker/ubuntu.xml" \
migration_transport=tcp meta allow-migrate=true
Просмотреть список добавленных ресурсов
sudo pcs status
sudo pcs resource show ubuntu
Проверить список виртуальных машин на узле, на котором запустился ресурс:
sudo virsh list --all
Задание 5. Настройка динамической миграции
Необходимо перейти в файл /etc/libvirt/libvirtd.conf
sudo vi /etc/libvirt/libvirtd.conf
Добавить туда три параметра:
listen_tls = 0
listen_tcp = 1
auth_tcp = "none"
Сохранить файл. После этого необходимо изменить файл /etc/default/libvirtd
sudo vi /etc/default/libvirtd
Добавить параметр:
LIBVIRTD_ARGS="--listen --config /etc/libvirt/libvirtd.conf"
Перезагрузить libvirt.
sudo systemctl mask libvirtd.socket libvirtd-ro.socket libvirtd-admin.socket libvirtd-tls.socket libvirtd-tcp.socket
sudo systemctl restart libvirtd
Проделать эти операции на всех узлах.
Задание 6. Миграция ресурса
Нужно переместить ресурс на labnode-2:
sudo pcs resource move ubuntu labnode-2
На labnode-2 посмотреть статус кластера, и проверить список запущенных гостевых машин можно следующими командами:
sudo pcs status
sudo virsh list --all
Команда move добавляет ресурсу правило, заставляющее его запускаться только на указанном узле. Для того чтобы очистить все добавленные ограничения - clear:
sudo pcs resource clear ubuntu
Необходимо дождаться загрузки VM. Переместить ресурс на labnode-1:
sudo pcs resource move ubuntu labnode-1
Посмотреть на результат:
sudo pcs status
sudo virsh list --all
Задание 7. Развертывание вложенной инфраструктуры
Аналогичным образом как было описано ранее, необходимо дополнительно развернуть виртуальные машины и привести к виду
Параметры VM, аналогичны созданной ранее VM(ubuntu)
Все созданные виртуальные машины должны находится в кластере
Задание 8. Развертывание frontend
Подключаемся на созданную ранее виртуальную машину на узле Labnode-2
Устанавливаем утилиту для работы с системой контроля версий GIT
sudo apt install -y git
Склонируем с помощью Git публичный репозиторий и перейдем в нее
git clone https://gitlab.resds.ru/itt/sample-front.git
cd sample-front
Установим NodeJS-18
# Добавляем репозиторий
curl -s https://deb.nodesource.com/setup_18.x | sudo bash
# Устанавливаем пакет
sudo apt install nodejs -y
# Проверяем установку
node -v
Устанавливаем пакеты node-js
npm ci
Запускаем проект
npm start
Проверьте запуск веб приложения используя браузер
Задание 9. Развертывание backend
- Необходимо на виртуальной машине backend скопировать репозиторий
https://gitlab.resds.ru/itt/sample-back.git - Установить NodeJs 18
- Установить все используемые пакеты
- Запустить проект с помощью команды
npm run
- Проверить работоспособность backend Для выполнения проверки работоспособности можно выполнить команду, для добавления заметки и просмотра списка заметок
- Добавление заметки
curl --location --request POST 'http://127.0.0.1:5000/api/notes' \
--header 'Content-Type: application/json' \
--data-raw '{
"index": "1",
"note": "test message"
}'
- Проверка списка заметок
curl --location --request GET 'http://127.0.0.1:5000/api/notes'
Задание 10. Развертывание NGINX
- Установить веб-сервер NGINX
sudo apt install nginx - Изменяем конфигурацию NGINX
/etc/nginx/conf.d/defautl.confupstream front { server notes-app:3000; } upstream back { server notes-back:5000; } server { listen 80; location / { proxy_pass http://front; proxy_set_header Host $host; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Real-IP $remote_addr; } location /api { proxy_pass http://back/api; proxy_set_header Host $host; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Real-IP $remote_addr; } }
Можно произвести проверку синтаксиса с помощью команды
nginx -c /etc/nginx/conf.d/default.conf
в конфигурации необходимо изменить
notes-appиnotes-backна адреса VM
- Проверьте работы приложения при миграции виртуальных машин и выключение хостовой виртуальной машины
Контейнеризация приложений
Построение стенда
Схема виртуального лабораторного стенда

Рисунок 1. Схема стенда
- Создать виртуальные машины для работы
| Название виртуальной машины | Источник | Тип инстанса | Сети для внешнего подключения |
|---|---|---|---|
| web-server | Образ-Ubuntu-server20.04 | medium | external-net |
Так же нужно проверить развернутую инфраструктуру на соответствие схеме на рисунке 1.
1. Установка Docker
-
Обновляем информацию о пакетах в репозиториях и обновляем установленные пакеты:
sudo apt update sudo apt full-upgrade -y -
Добавляем репозитории официальные репозитории Docker:
sudo install -m 0755 -d /etc/apt/keyrings sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc sudo chmod a+r /etc/apt/keyrings/docker.asc echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \ $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo apt-get update -
Установим пакеты Docker
sudo apt install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin -y -
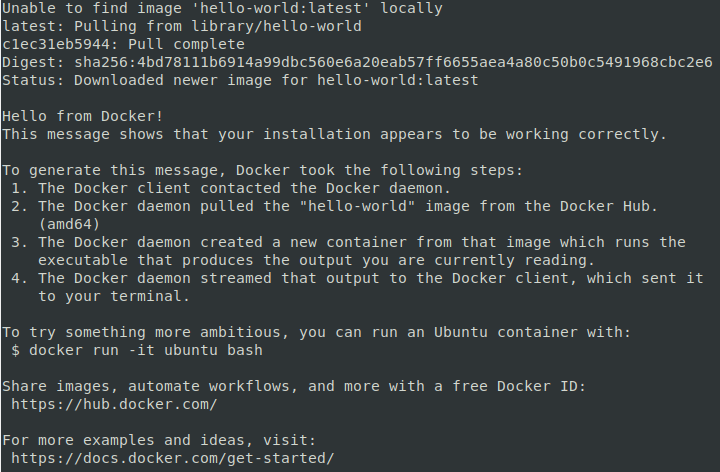
Проверка работы Docker
sudo docker run hello-world
-
Добавляем пользователя в группу
dockersudo groupadd docker sudo usermod -aG docker $USERПосле того как текущий пользователь был добавлен в группу Docker, мы можем проверить функциональность Docker без необходимости использования привилегий суперпользователя.
docker run hello-world
2. Написание Dockerfile
-
Клонируем исходный проект с использованием системы контроля версий Git.
sudo apt install git -y git clone https://gitlab.resds.ru/itt/sample-project.git cd sample-projectв данном проекте собраны все компоненты из прошлой работы
-
Пишем Dockerfile для frontend части проекта Для выполнения этой задачи предлагаем создать файл с названием Dockerfile в директории notes-app.
FROM node:18-slim WORKDIR /usr/local/app COPY package*.json ./ RUN npm i && npm cache clean --force COPY . . RUN npm run build -- --prod CMD ["npx","serve","-s","build"] -
Запускаем сборку контейнера и проверяем его работоспособность
docker build -t notes-app:latest . docker run -p 3000:3000 notes-app:latestИ проверяем работоспособность приложения открыв в браузере страницу
-
Проделываем аналогичные действия для notes-backend
FROM node:18-slim WORKDIR /usr/local/app COPY package*.json ./ RUN npm i && npm cache clean --force COPY . . CMD ["npm","start"]Собираем контейнер и проверяем
docker build -t notes-back:latest . docker run -p 5000:5000 notes-back:latestДля проверки можно использовать запрос к API
curl --location --request POST 'http://127.0.0.1:5000/api/notes' \ --header 'Content-Type: application/json' \ --data-raw '{ "index": "1", "note": "test message" }'Как можно заметить, приложения, запущенные внутри виртуальной машины, становятся доступными извне.
-
Создаем общий файл Docker-compose для запуска приложения.
services: notes-app: build: ./notes-app/ restart: always notes-back: build: ./notes-backend/ restart: always nginx: image: nginx:1.25.3-alpine-slim volumes: - ./nginx/default.conf:/etc/nginx/conf.d/default.conf ports: - "80:80" restart: always depends_on: - notes-app - notes-backС учетом данного способа запуска контейнеров следует обратить внимание на то, что только порт 80 становится общедоступным.
Система контроля версий GIT
В этих заданиях Вы будете осваивать основы работы с Git, от создания репозитория и фиксации изменений до ветвления, слияния и совместной работы. Вы также научитесь управлять удаленными репозиториями, откатывать изменения и управлять версиями проекта. Каждое задание представляет собой шаг к освоению полного цикла разработки с использованием Git, что позволит вам эффективно управлять версиями и совместно работать над проектами.
Ниже будет представлено несколько задач на освоение разных аспектов работы git:
- Команды: init, config, status, add, commit
- Команды: branch, checkout, status, log, diff
- Команды: restore, rm, reset, checkout, commit, revert
- Команды: merge, rebase
- Команды: clone, fetch, push, pull, remote
Задача 1.Команды: init, config, status, add, commit
Скачать и разархивировать архив
curl -l -O https://s3.resds.ru/itt/git-task1-1.tar.gz
Получившейся структура каталога:
cloudadmin@git:~$ tree task1-1
task1-1
├── index.html
└── pictures
├── elephant.jpg
├── giraffe.jpg
└── paw_print.jpg
Если попробовать открыть данный файл, то получится

В ходе задания будет необходимо создать на основе директории task1-1 репозиторий Git и внести в него некоторые изменения, после чего зафиксировать их средствами Git. Далее приводим само условие задачи:
Задачи:
-
Создайте репозиторий внутри папки
task1-1. Убедитесь, что внутри папкиtask1-1появилась папка .git. -
Настройте пользователя Git на уровне репозитория wild_animals:
- Изучите содержимое файла конфигурации Git для текущего репозитория (.git/config)
- Настройте имя и email пользователя для текущего репозитория
- Убедитесь, что файл .git/config изменился соответствующим образом
-
Изучите содержимое папки .git/objects
- Убедитесь, что отсутствует файл индекса (.git/index)
- Убедитесь, что папка с объектами Git пустая (.git/objects)
- Убедитесь, что указатель HEAD указывает на ветку main
-
Сделайте 1й коммит:
- Сделайте файлы папки wild_animals отслеживаемыми
- Обратите внимание на файл индекса (.git/index) и папку с объектами (.git/objects)
- Сделайте коммит
- Найдите хэш коммита и используйте его в сообщение к следующему коммиту
-
Сделайте 2й коммит
- Исправьте опечатку в файле index.html (опечатка в слове Elephant)
- Добавьте изменения в индекс
- Сделайте коммит
-
Сделайте 3й коммит
- Добавьте в файл index.html секцию для еще одного животного (кенгуру)
- Добавьте изменения в индекс
- Сделайте коммит
-
Перейдите на https://gitlab.resds.ru/ и авторизуйтесь
-
Нажмите на создание нового проекта(репозитория)
 После этого выберите создание пустого проекта:
После этого выберите создание пустого проекта:
 Назовите проект
Назовите проект task1-1и отключите созданияreadme.md, и уровень видимости установите вPublic После этого необходимо добавить удаленный репозиторий
После этого необходимо добавить удаленный репозиторийgit remote add origin git@gitlab.resds.ru:tarabanov.if/task1-1.gitгде
git@gitlab.resds.ru:tarabanov.if/task1-1.git, это путь к вашему репозиториюИ пушим изменения в удаленный репозиторий
git push --set-upstream origin --all
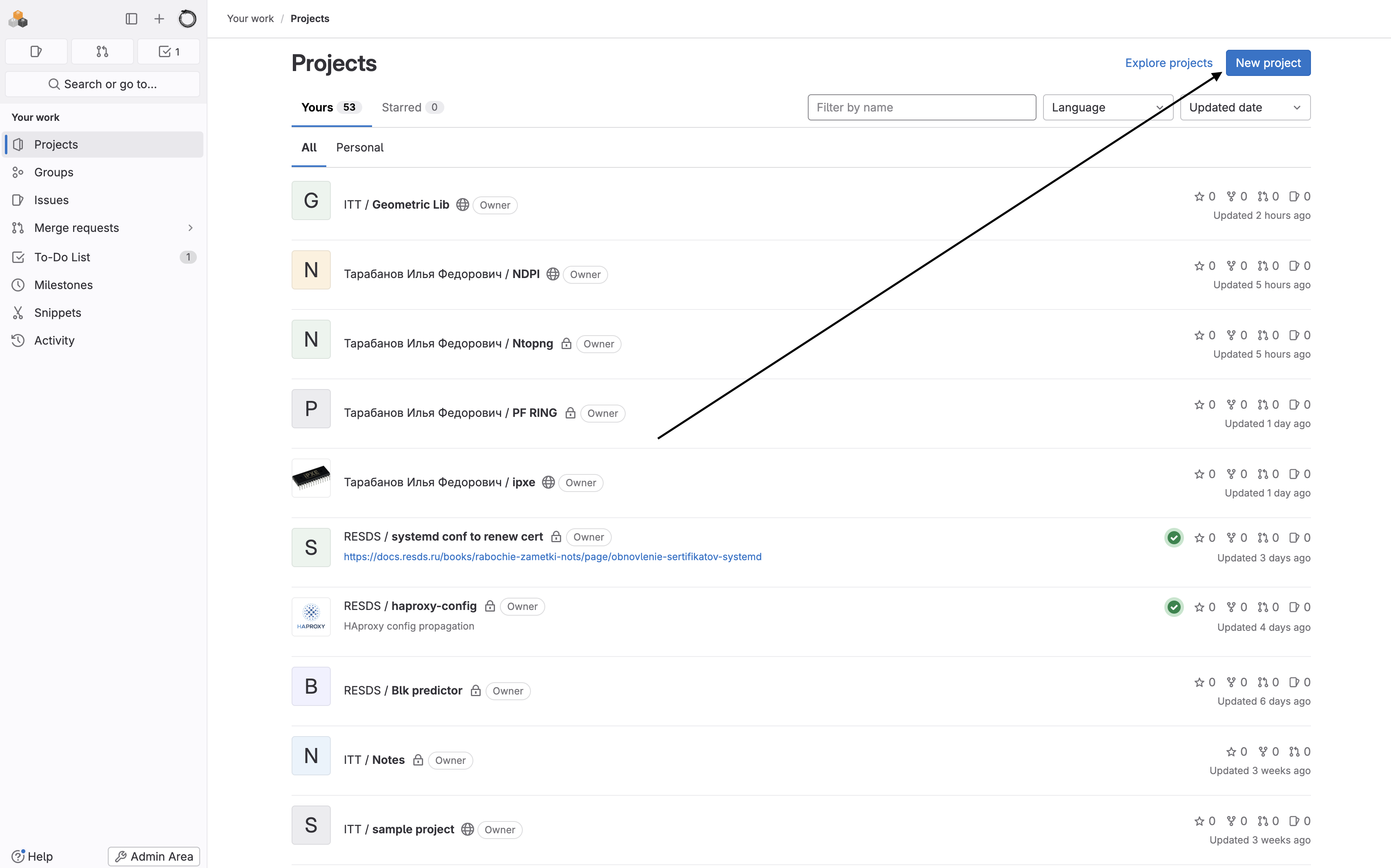
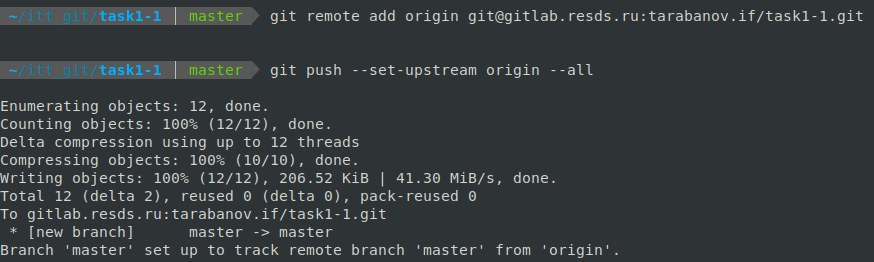
Задача 2. Команды: init, config, status, add, commit
Скачать и разархивировать архив
curl -l -O https://s3.resds.ru/itt/git-task1-2.tar.gz
Дана маленькая библиотека, вычисляющая некоторые тригонометрические функции. Она имеет следующую структуру: Структура директории mat_lib;
cloudadmin@git:~$ tree mat_lib
task1-2
├── docs
│ └── math_lib_docs.txt
└── pyfiles
├── factorial.py
├── test.py
└── trigonometry.py
2 directories, 4 files
Назначение каждого из файлов:
-
math_lib_docs.txtКороткая документация по функционалу библиотеки -
factorial.pyМодуль с функцией factorial(), которая вычисляет факториал переданного числа -
trigonometry.pyМодуль с тригонометрическими функциями, например, sin() -
test.pyМодуль для проверки функционала тригонометрических функций для разных значений углов
Далее можно увидеть содержимое файлов:
Содержимое файла math_lib_docs.txt:
This is the library which designation is to implement some math functions
Содержимое файла factorial.py:
def factorial(x):
ans = 1
if x < 0:
raise ValueError('x must be greater than 0')
for i in range(1, x+1):
ans *= i
return ans
Содержимое файла trigonometry.py:
from factorial import factorial as fct
def sin(x):
sin = 1 - (x**2/fct(2)) + (x**4/fct(4)) - (x**6/fct(6)) + (x**8/fct(8)) - (x**10/fct(10))
return round(sin, 5)
Содержимое файла test.py:
from trigonometry import sin
import math
pi = math.pi
print('pi:', pi)
for alpha in [0, pi, pi/2, pi/3, pi/4, pi/6]:
print(f'For angle: {0 if alpha == 0 else "pi/"+str(int(pi/alpha))}, Sine is ~ {sin(alpha)}')
Задачи:
-
Инициализируйте репозиторий в папке mat_lib
-
Задайте имя пользователя и email глобально
- Проверьте, что изменения внесены в файл глобальных настроек .gitconfig
- Проверьте, что файл локальных настроек .git/config не был изменен
-
Изучите содержимое папки .git/
- Узнайте, на что сейчас указывает HEAD
- Просмотрите файл, на который указывает HEAD
-
Добавьте все файлы в индекс
-
Сделайте первый коммит
- Просмотрите объект коммита, найдите хэш объекта-дерева корня репозитория
- Просмотрите объект дерева корня репозитория
- Проверьте, на что указывает HEAD сейчас
- Просмотрите файл, на который указывает HEAD
- Ответьте на вопрос: на что указывает текущая ветка? Для этого просмотрите на объект, на который указывает ветка.
-
Выполните файл test.py
- Просмотрите статус файлов, чтобы обнаружить, что появились файлы кэша
-
Сделайте второй коммит
- Просмотрите объект коммита, найдите хэш родительского коммита
- Посмотрите, на что сейчас указывает HEAD
- Проверьте файл, на который указывает HEAD
- Узнайте, на что указывает текущая ветка. Для этого просмотрите на объект, на который указывает ветка.
- Создайте и опубликуйте свое репозиторий на https://gitlab.resds.ru/
Задача 3 Команды: branch, checkout, status, log, diff
Дана библиотека, написанная на Python - Geometric Lib. Файловая структура данной библиотеки: Структура папки geometric_lib:
cloudadmin@git:~$ tree geometric_lib
geometric_lib
├── circle.py
├── docs
│ └── README.md
└── square.py
1 directory, 3 files
В качестве задания необходимо выполнить ряд действий над репозиторием geometric_lib: создадим новую ветку, сделаем коммиты, посмотрим историю и изучим внесенные изменения средствами Git.
Задачи
-
Выполните команду
git clone https://gitlab.resds.ru/itt/geometric_lib.git. -
Создайте новую ветку с названием new_features и переключитесь на нее.
-
Добавьте новый файл в эту ветку.
Например, с вычислениями для фигуры Прямоугольник. Его название: rectangle.py Его содержимое:
def area(a, b): return a * b def perimeter(a, b): return a + b -
Сделайте коммит с сообщением "L-03: Added rectangle.py".
-
Добавьте еще один файл в эту ветку.
Например, с вычислениями для фигуры Треугольник. Его название: triangle.py Его содержимое:
def area(a, h): return a * h / 2 def perimeter(a, b, c): return a + b + c -
Исправьте ошибку в вычислении периметра в файле rectangle.py, теперь он должен стать таким:
def area(a, b): return a * b def perimeter(a, b): return 2 * (a + b) -
Создайте еще один коммит внутри этой же ветки, его сообщение:
"L-03: Added triangle.py and fixed rectangle perimeter bug". -
Постройте граф истории всего репозитория с однострочным выводом коммитов.
-
Постройте граф истории только текущей ветки. В ней должно быть два последних коммита.
-
Возьмите хэши двух последних коммитов из истории и посмотрите, какие изменения были внесены.
-
Создайте репозиторий на https://gitlab.resds.ru/
-
Смените удаленный репозиторий на созданный на прошлом шагу
-
Пушните изменения и смерджите созданную ветку, без удаления ветки
Задача 4. Команды: git restore, git rm, git reset, git checkout, git commit, git revert
Дана библиотека, написанная на Python - Geometric Lib. Файловая структура данной библиотеки: Структура репозитория geometric_lib:
# Ветка main (Основная стабильная ветка)
geometric_lib
├── circle.py
├── square.py
└── docs
└── README.md
# Ветка develop (Ветка разработки)
geometric_lib
├── circle.py
├── square.py
└── docs
└── README.md
└── calculate.py
# Ветка feature (Ветка для новых функций)
geometric_lib
├── circle.py
├── square.py
└── docs
└── README.md
└── rectangle.py
В качестве задания необходимо выполнить ряд действий над репозиторием geometric_lib: изучить его структуру, откатить ненужные коммиты, объединить некоторые коммиты в один, перенести файлы из одной ветки в другую и т д.
Задачи
-
Выполните
git clone https://gitlab.resds.ru/itt/geometric_lib.gitПереключитесь на ветки
featureиdevelop -
Постройте полный граф истории, чтобы познакомиться со структурой коммитов.
-
Работа с веткой
featureВ последнем коммите ветки feature допущена ошибка. Откатите этот неудачный коммит.
-
Работа с веткой develop
Теперь заметьте, что у нас есть два коммита в ветке develop одной и той же тематики: "L-04: Add calculate.py", "L-04: Update docs for calculate.py".
Объедините их в один коммит и напишите к нему пояснение. -
Эксперименты. Работа с файлами calculate.py и rectangle.py в ветке experiments <BR>Ветку develop мы привели в порядок. Теперь давайте представим, что мы хотим протестировать совместную работу файлов
calculate.pyиrectangle.py. Чтобы не мешать работе других файлов, создадим отдельную веткуexperiment, которая будет брать начало в конце веткиmain. Новая ветка будет хранить коммиты с результатами наших экспериментов. Задания:-
Создайте новую ветку с именем
experiment.
Как было сказано выше, она пригодится нам, чтобы хранить наши экспериментальные коммиты. -
Мы хотим провести эксперименты с файлом calculate.py, но текущая документация (файл
docs/README.md) устарела.
Добавьте в нашу рабочую копию документацию, которая содержит информацию о файлеcalculate.py.
Такая есть, например, в последнем коммите веткиdevelop.
Для этого скопируйте файлdocs/README.mdиз последнего коммита веткиdevelopв рабочую копию. -
Добавьте в индекс и рабочую копию файл
calculate.pyиз последнего коммита веткиdevelop. -
Добавьте все нужные файлы в индекс и сделайте коммит.
-
-
Создайте репозиторий на https://gitlab.resds.ru/
-
Смените удаленный репозиторий на созданный на прошлом шагу
-
Запушьте изменения
Задача 5.Команды: git merge, git rebase
Дана библиотека, написанная на Python - Geometric Lib. Файловая структура данной библиотеки: Структура репозитория geometric_lib:
# Ветка main (Основная стабильная ветка)
geometric_lib
├── circle.py
├── square.py
└── docs
└── README.md
# Ветка develop (Ветка разработки)
geometric_lib
├── circle.py
├── square.py
└── docs
└── README.md
└── calculate.py
# Ветка release
geometric_lib
├── circle.py
├── square.py
└── docs
└── README.md
└── user_agreement.txt
Задачи
-
Выполните
git clone https://gitlab.resds.ru/itt/geometric_lib.gitПереключитесь на ветки
releaseиdevelop -
Работа с веткой
develop- Постройте полный граф истории, чтобы познакомиться со структурой коммитов.
- Влейте ветку
developв ветку main явным образом (с созданием merge-коммита). - Удалите коммит слияния, чтобы затем выполнить слияние в
fast-forwardрежиме. - Влейте ветку
developв веткуmainнеявным образом (без создания merge-коммита - в режимеfast-forward).
-
Работа с веткой release
- Выполните интерактивный ребейз ветки
releaseна веткуmain- объедините все коммиты в один и поменяйте их общее сообщение. Разрешите конфликты. - Выполните
fast-forwardслияние ветки release в веткуmain.
- Выполните интерактивный ребейз ветки
Задача 6.git clone, git fetch, git push, git pull, git remote
Дана библиотека, написанная на Python - Geometric Lib. В качестве задания необходимо выполнить ряд действий над репозиторием geometric_lib. Файловая структура данной библиотеки: Структура репозитория geometric_lib:
# Ветка main (Основная стабильная ветка)
geometric_lib
├── circle.py
├── square.py
└── docs
└── README.md
# Ветка develop (Ветка разработки)
geometric_lib
├── circle.py
├── square.py
└── docs
└── README.md
└── calculate.py
# Ветка release
geometric_lib
├── circle.py
├── square.py
└── docs
└── README.md
└── user_agreement.txt
Задачи
-
перейдите на страницу https://gitlab.resds.ru/itt/geometric_lib и создайте свой форк
-
Склонируйте к себе свой форк репозитория
geometric_lib. -
Настройте локального пользователя Git
-
Измените файл
docs/README.md. Сделайте коммит. -
Выполните пуш ваших изменений в свой удаленный репозиторий.
-
Откройте страницу вашего репозитория. Можете убедиться, что изменения были успешно загружены в удаленный репозиторий, просмотрев историю коммитов на главной странице репозитория.
-
Смените тип получения данных из репозитория с
sshнаhttpsили наоборот. Смотря от первоначального метода подключения -
Повторно измените
docs/README.md. Сделайте коммит. -
Выполните пуш ваших изменений в свой удаленный репозиторий.
-
Откройте страницу вашего репозитория и проверьте внесенные изменения
-
Создайте пулл-реквест. В нем подробно опишите внесенные изменения. На странице предпросмотра пулл-реквеста проверьте, что вы не затронули файлы на других ветках и еще раз перепроверьте код
Управление инфраструктурой. Terraform.
Описание стенда

Подготовка окружения
-
Установите vscode
-
Установите плагин Remote SSH
-
Создайте VM для роли управления terraform
-
Добавить конфигурацию узла в VScode с ранее созданным узлом
Если при подключении запрашивается пароль, то можно модифицировать конфигурацию ssh(
~/.ssh/config)Host 172.17.* User cloudadmin IdentityFile ~/.ssh/id_ed25519В
IdentityFileнужно вписать путь до вашего приватного ключа -
Подключитесь к узлу без указания конкретного пользователя


-
Во вкладке с файлами откройте домашнюю директорию пользователя
cloudadmin
-
Установите на узле плагин terraform от hashicorp

Установка terraform
- Перейти на сайт: https://developer.hashicorp.com/terraform/install
- Убеждаемся, что HashiCorp не очень любит Россию и либо пользуемся зеркалом https://cloud.vk.com/docs/manage/tools-for-using-services/terraform/quick-start (первый пункт)
либо скачиваем с google дискаcurl -l -O https://hashicorp-releases.mcs.mail.ru/terraform/1.7.4/terraform_1.7.4_linux_amd64.zippip install gdown gdown https://drive.google.com/uc?id=1W6z0_-DDcEobFHoNz4lErO1wMHF2wnyc - Разархивируем
sudo unzip terraform_1.7.4_linux_amd64.zip -d /usr/local/bin - Проверим, что все установилось

Подготовка terraform
-
Добавим зеркало для работы с terraform без vpn
Создаем файл
.terraformrctouch ~/. terraformrcЗаполним содержимое:
provider_installation { network_mirror { url = "https://terraform-mirror.mcs.mail.ru" include = ["registry.terraform.io/*/*"] } direct { exclude = ["registry.terraform.io/*/*"] } } -
Создать директорию
terraform_openstackи в ней файлы:data.tf,main.tf,outputs.tf,provider.tf,variables.tf
-
Заполнить
provider.tfterraform { required_version = ">= 0.14.0" required_providers { openstack = { source = "terraform-provider-openstack/openstack" version = "~> 1.53.0" } } } -
Выполнить команду
terraform initи убедиться что все прошло успешно
-
Перейти в openstack в меню API ACCESS
 Скачайте
Скачайте clouds.yml
Добавить его в рабочую директорию и добавить графуpassword
-
в
provider.tfдобавьте директивуprovider "openstack" { cloud = "openstack" }
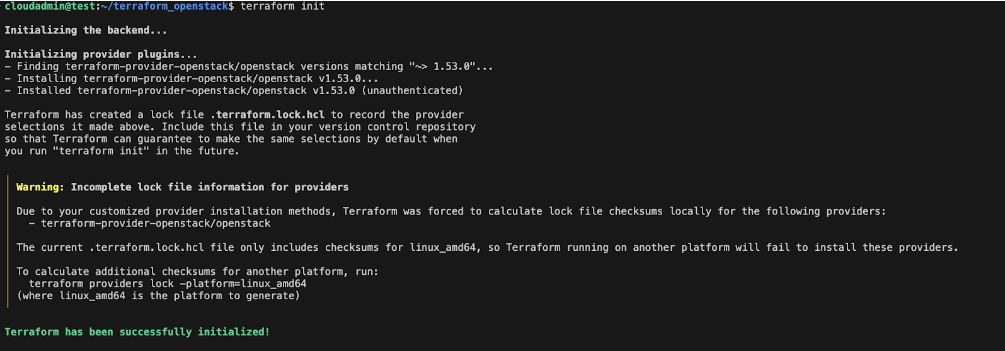
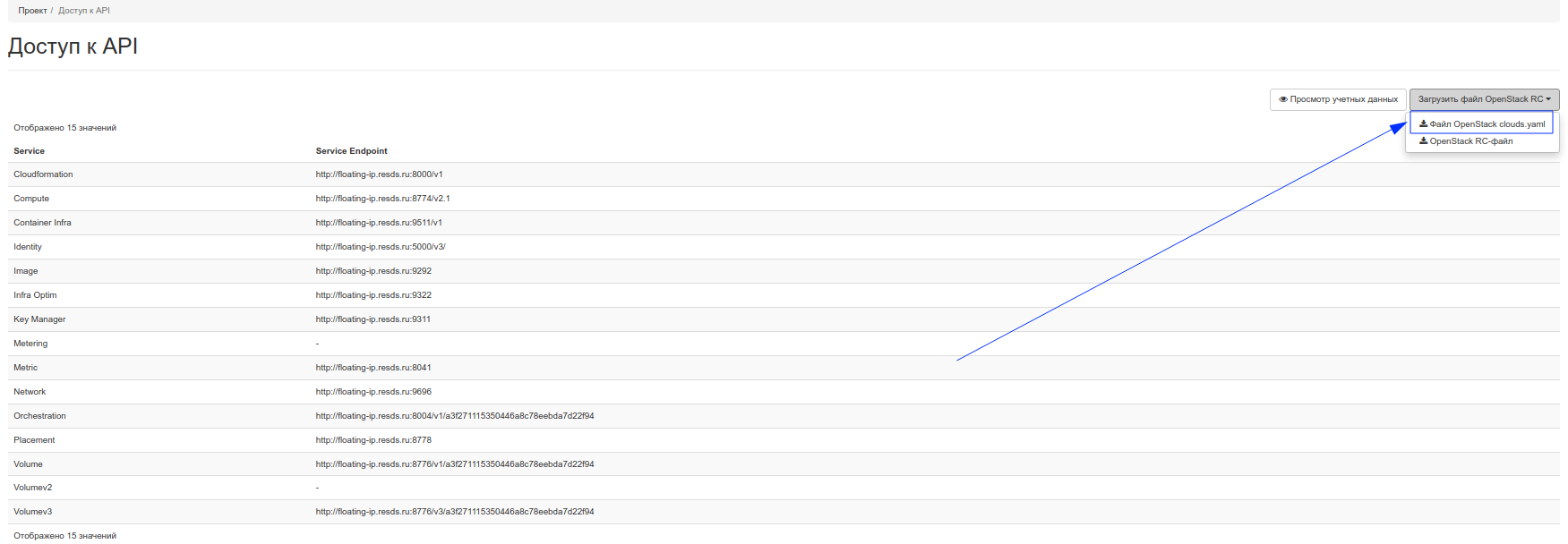
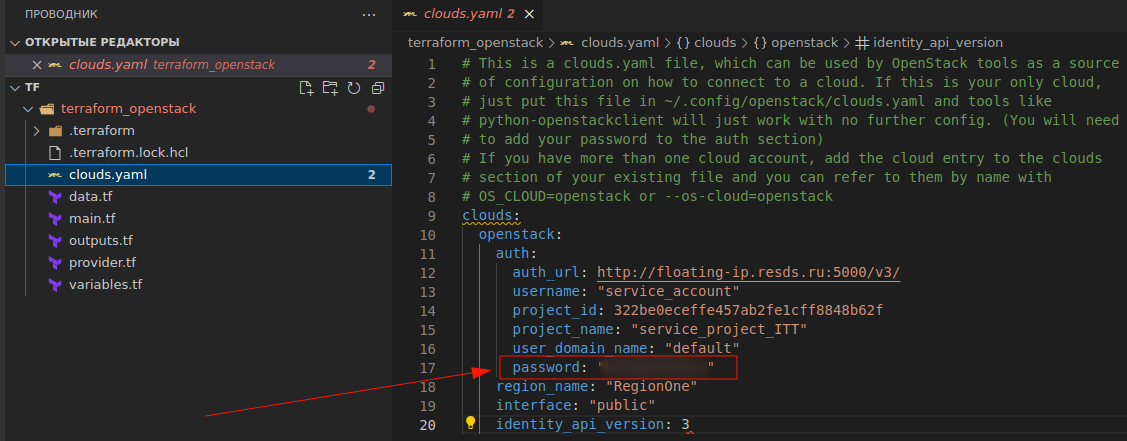
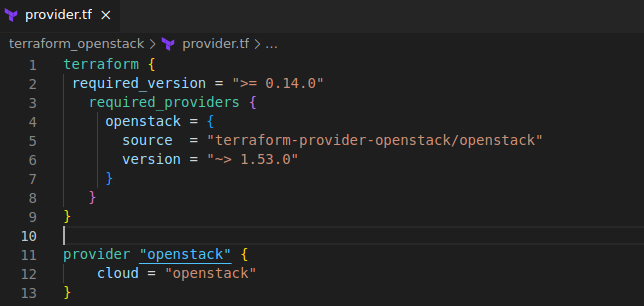
Задание 1.
Чтобы создать виртуальную машину, нам нужен какой-то образ, в openstack образы можно называть одинаково, но вот id образов будет разный, необходимо получить id необходимого нам образа Для этого пользуемся документацией(она работает тоже только с vpn или прокси) https://registry.terraform.io/providers/terraform-provider-openstack/openstack/latest/docs/data-sources/images_image_v2
В моем случае я буду пользоваться Ubuntu-server-20.04
Суть задания, добавить переменную с названием образа, создать data source образа и вывести его id в outputs
Пример:
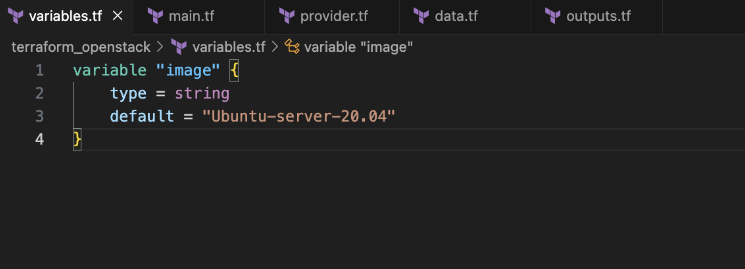
variable "image" {
type = string
default = "Ubuntu-server-20.04"
}
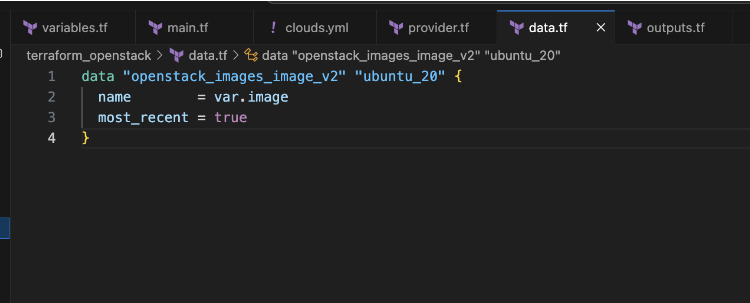
data "openstack_images_image_v2" "ubuntu20" {
name = var.image
most_recent = true
}
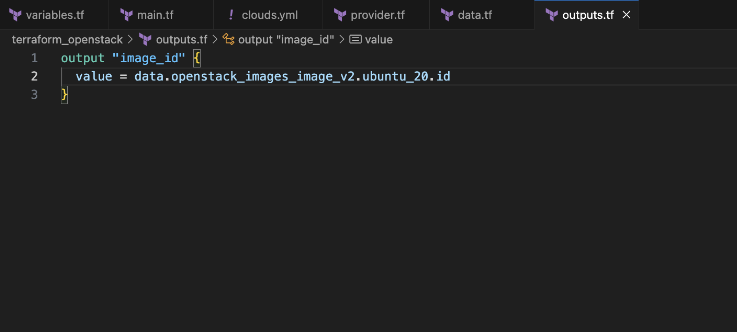
output "image_id" {
value = data.openstack_images_image_v2.ubuntu20.id
}
Выполнить terraform plan и убедиться что именно это мы и хотели создать
 Ну и выполняем(
Ну и выполняем(terraform apply):
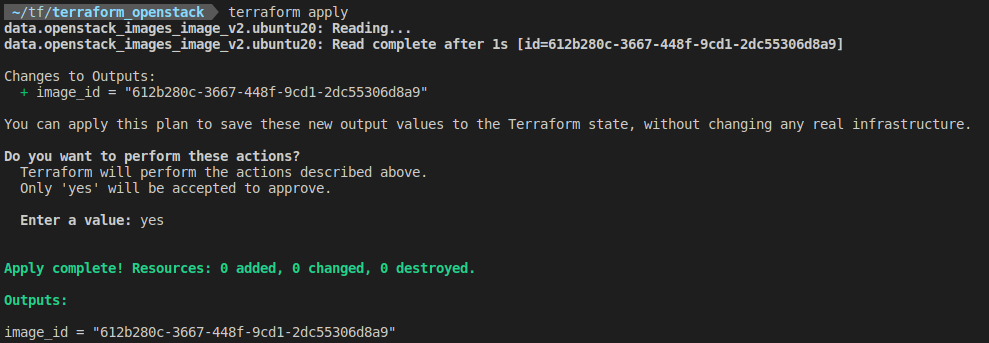
Задание 2
Создать 2 виртуальные машины. Ссылка: https://registry.terraform.io/providers/terraform-provider-openstack/openstack/latest/docs/resources/compute_instance_v2
Требования:
- Ресурсы создать в main.tf
- Flavor должен быть small
- Id образа не вписывать в ручную
- У машин должен быть разный образ, но обе должны быть ubuntu
- У машин должен быть разный объем диска
- Outputs должен быть вида: имя машины: IP адрес машины, дополнительные сведения можно добавить по желанию
- В переменные необходимо занести: объем диска, имя машин
- Убедиться, что к машинам можно подключиться по ssh
Задание 3:
Удалить все что создали с помощью terraform
Управление инфраструктурой. Ansible.
Задание 0. Построение стенда
Схема виртуального лабораторного стенда

Рисунок 1. Схема стенда
1. Создать виртуальный стенд для работы
| Название виртуальной машины | Источник | Тип инстанса | Сети для внешнего подключения | Размер диска |
|---|---|---|---|---|
| Ansible | Образ-Ubuntu-server20.04 | small | external-net | 15GB |
| node1 | Образ-Ubuntu-server20.04 | small | external-net | 15GB |
| node2 | Образ-CentOS-7 | small | external-net | 15GB |
2. Установить ANSIBLE
Ниже будут представлены несколько способов установки Ansible. От выбора метода установки зависит удобство использования и доступные функции, поэтому важно выбрать оптимальный способ в соответствии с вашими потребностями и предпочтениями и операционной системы
PIP
- Проверить наличие
pythonна узле:python3 -v - При отсутствии
python, его необходимо установить:sudo apt install python3 - Проверяем наличие менеджера пакетов
pip:python3 -m pip --version - При отсутствии
pip, его необходимо установить:sudo apt install python3-pip
При наличии python с менеджером пакетов pip, можно установить используя его.
Для установки с помощью pip необходимо ввести команду
python3 -m pip install --user ansible
При необходимости можно установить пакет ansible-core он отличается тем, что с помощью него возможно использовать только язык и рантайм Ansible, и отсутствует интеграция с galaxy
python3 -m pip install --user ansible-core
Ansible и Ansible Core тесно связаны, но есть небольшая разница между ними. Ansible Core представляет собой базовый движок автоматизации, который включает основные функции управления конфигурациями и выполнения задач через SSH. Он является основой для всей экосистемы Ansible. С другой стороны, Ansible как платформа включает в себя не только ядро, но и дополнительные инструменты, модули, плагины и библиотеки, расширяющие функциональность и возможности автоматизации. Таким образом, Ansible Core представляет собой базовую часть, в то время как Ansible включает в себя эту базу и дополнительные компоненты для расширения функциональности и упрощения управления инфраструктурой.
Ubuntu
Для установки на Ubuntu можно использовать стандартный менеджер пакетов apt
sudo apt update
sudo apt install software-properties-common
sudo add-apt-repository --yes --update ppa:ansible/ansible
sudo apt install ansible
Debian
Репозиторий debian стал deprecated, возможно использование обходных путей для установки пакета
| Debian | Ubuntu | UBUNTU_CODENAME |
|---|---|---|
| Debian 12 (Bookworm) | Ubuntu 22.04 (Jammy) | jammy |
| Debian 11 (Bullseye) | Ubuntu 20.04 (Focal) | focal |
| Debian 10 (Buster) | Ubuntu 18.04 (Bionic) | bionic |
Пример для Debian12
UBUNTU_CODENAME=jammy
wget -O- "https://keyserver.ubuntu.com/pks/lookup?fingerprint=on&op=get&search=0x6125E2A8C77F2818FB7BD15B93C4A3FD7BB9C367" | sudo gpg --dearmour -o /usr/share/keyrings/ansible-archive-keyring.gpg
echo "deb [signed-by=/usr/share/keyrings/ansible-archive-keyring.gpg] http://ppa.launchpad.net/ansible/ansible/ubuntu $UBUNTU_CODENAME main" | sudo tee /etc/apt/sources.list.d/ansible.list
sudo apt update && sudo apt install ansible
Проверка установки ansible
ansible --version
3. Минимальная настройка ANSIBLE
Хоть Ansible может работать из коробки и не требует дополнительной настройки, мы выполним настройки которые улучшат опыт использования системы автоматизации для этого мы можем использовать конфигурационные параметры и они могут храниться в различных местах:
-
ANSIBLE_CONFIG (переменная окружения)
-
ansible.cfg (в текущем каталоге, откуда происходит запуск)
-
~/.ansible.cfg (в домашнем каталоге пользователя)
-
/etc/ansible/ansible.cfg
В ходе работы мы предлагаем такой конфиг, его необходимо разместить в домашней директории пользователя:
[defaults] # Отключение проверки хостовых ключей SSH. Позволяет Ansible подключаться к хостам без подтверждения их хостовых ключей. host_key_checking = False # Настройка метода сбора информации о системе хоста. "smart" означает автоматически определить наилучший метод, исходя из условий. gathering = smart # Указание метода передачи данных между хостами. transfer_method = piped # Настройка параметров SSH. ssh_args = "-o ControlMaster=auto -o ControlPersist=60s" # Максимальное количество параллельных процессов (форков) Ansible. Определяет, сколько хостов может обрабатываться параллельно. forks = 20Тут представлена малая часть параметров которые можно использовать, полный список можно получить в документации https://docs.ansible.com/ansible/latest/reference_appendices/config.html
4. Написание инвентари
Ansible использует файлы инвентаря для определения групп хостов и их параметров. Создайте файл inventory.ini и определите в нем хосты, с которыми будет взаимодействовать Ansible:
[node]
# Добавление узла с именем web и ip адресом 172.17.5.5
node1 ansible_host=172.17.5.5
[all:vars]
# Добавление общей переменной для всех хостов в inventory, с указанием общего имени пользователя
ansible_user = cloudadmin
Проверить inventory, можно использовав встроенный модуль ansible ping:
ansible -i inventory.ini all -m ping
Пример валидного ответа

Также можно получить всю существующую информацию об хостах:
ansible -i inventory.ini all -m setup
Установить пакет git используя модуль apt:
ansible all -i inventory.ini -m apt -a "name=git state=present" --become
Опция
--becomeв командах Ansible используется для выполнения задач с привилегиями суперпользователя (обычно root). Грубо говоря как использованияsudoпри работе в терминале.
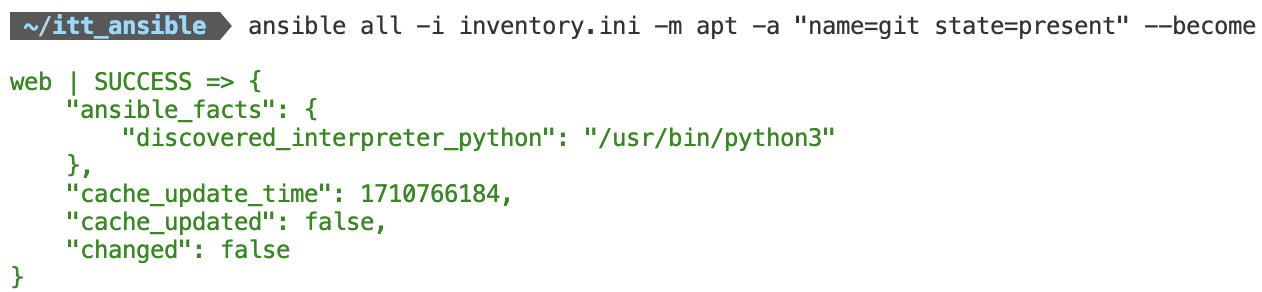
Выполнить команду ss -tulpan на удаленных узлах:
ansible all -i inventory.ini -m command -a "ss -tulpan" --become
5. Написание плейбуков
Плейбуки в Ansible - это текстовые файлы в формате YAML, которые содержат описание задач, должны быть выполнены на целевых хостах. Их основное предназначение - автоматизация конфигурации и управления системами. Попробуем написать простой плейбук и будем его пополнять в процессе работы:
---
- name: Update packages
hosts: node
become: yes
tasks:
- name: Update all packages
apt:
update_cache: yes
upgrade: 'yes'
Для выполнения плейбука можно выполнить команду:
ansible-playbook playbook.yaml -i inventory.ini
Пример того, когда при выполнение плейбука обновляются пакеты:
 Пример выполнения плейбука, когда пакеты не были обновлены:
Пример выполнения плейбука, когда пакеты не были обновлены:

Можно заметить, что в данном случае плейбук состоит всего из одной задачи, но плейбуки могут состоять из множетсва задача, давайте добавим задачу для установки NGINX, и передачи ему конфигурации:
---
- name: Update packages
hosts: node
become: yes
tasks:
- name: Update all packages
apt:
update_cache: yes
upgrade: 'yes'
- name: Install nginx
ansible.builtin.apt:
package:
- nginx
state: present
update_cache: yes
- name: Copy config nginx
ansible.builtin.template:
src: nginx.conf.j2
dest: /etc/nginx/nginx.conf
Также можно заметить, что в последней строке происходит копирования файлов, нам необходимо создать файл nginx.conf.j2 и заполнить его:
user {{ nginx_user }};
worker_processes 2048;
worker_priority -1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections {{worker_connections}};
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
reset_timedout_connection on;
client_body_timeout 35;
send_timeout 30;
gzip on;
gzip_min_length {{gzip_min_length}};
gzip_vary on;
gzip_proxied expired no-cache no-store private auth;
gzip_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript application/javascript; gzip_disable "msie6";
types_hash_max_size 2048;
client_max_body_size {{client_max_body_size}};
proxy_buffer_size 64k;
proxy_buffers 4 64k;
proxy_busy_buffers_size 64k;
server_names_hash_bucket_size 64;
include /etc/nginx/conf.d/*.conf;
include /etc/nginx/sites-enabled/*;
}
Можно заметить, что в данном конфигурационном файле мы начинаем использовать переменные. Переменных могло быть и больше, но для демонстрации их использования, вполне, достаточно. Сами переменные заключены в двойные фигурные скобки и были нами определены в файле инвентари в данном случае (переменная nginx_user, будет определена в настройках плейбука инвентари, будет зависеть от установленной системы).
Модифицируем наш инвентари и добавим второй узел и переменные среды для node1:
[node]
node1 ansible_host=172.17.5.5 nginx_user=www-data
node2 ansible_host=172.17.5.6 nginx_user=root
[all:vars]
ansible_user = cloudadmin
Выполним плейпбук
ansible-playbook playbook.yaml -i inventory.ini
Во время, выполнения мы можем увидеть ошибку, связанную с тем, что centos использует yum, а не apt, как и все redhat семейство:
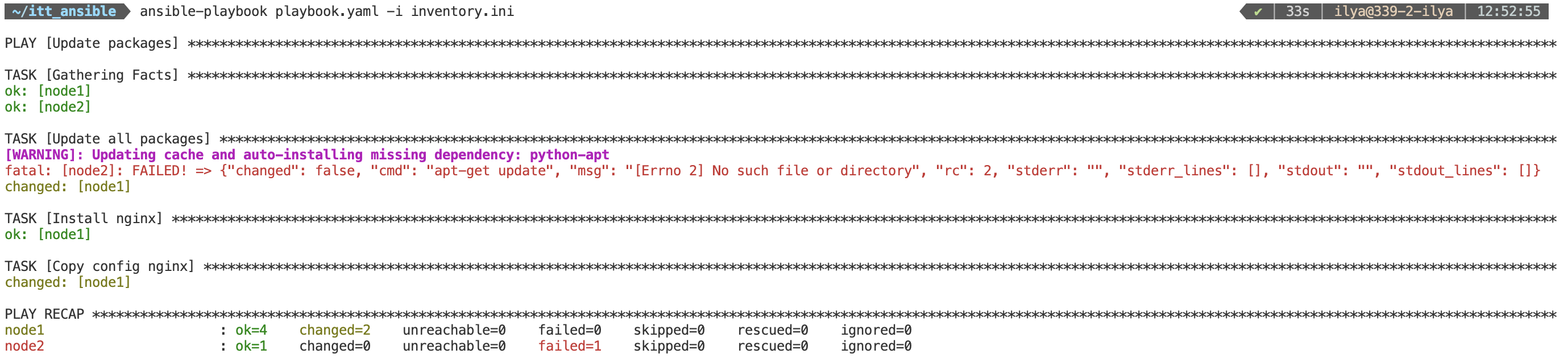
Для того, чтобы сделать плейбук более универсальным, нам необходимо добавить условия и сделать установку для семейства redhat и тогда плейбук, будет выглядеть так:
---
- name: Update packages
hosts: node
become: yes
tasks:
- name: Install nginx "Debian"
ansible.builtin.apt:
package:
- nginx
state: present
update_cache: yes
when: ansible_facts['os_family'] == "Debian"
- name: Install nginx "redhat"
ansible.builtin.yum:
name:
- nginx
state: present
when: ansible_facts['os_family'] == "RedHat"
- name: Copy config nginx
ansible.builtin.template:
src: nginx.conf.j2
dest: /etc/nginx/nginx.conf

Мы успешно освоили навык написания простых Ansible плейбуков, что позволяет нам автоматизировать рутинные операции и упрощает управление инфраструктурой, повышая эффективность и надежность работы.
6. Написание ролей
Для написания ролей в первую очередь можно создать роль с помощью ansible galaxy
ansible-galaxy init itt_labs
Посмотрим на созданную нами роль:
itt_labs/
├── defaults
│ └── main.yml
├── files
├── handlers
│ └── main.yml
├── meta
│ └── main.yml
├── README.md
├── tasks
│ └── main.yml
├── templates
├── tests
│ ├── inventory
│ └── test.yml
└── vars
└── main.yml
8 directories, 8 files
Данные папки в Ansible служат для структурирования и организации кода, обеспечивая четкое разделение между различными типами ресурсов и функциональными блоками в проекте автоматизации. Вот краткое описание каждой из папок:
-
defaults: Эта папка содержит файлы YAML, которые определяют значения по умолчанию для переменных, используемых в роли. Переменные, определенные здесь, могут быть переопределены пользователями роли. -
files: В этой папке хранятся файлы, которые не требуют обработки шаблонами и должны быть просто копированы на целевые хосты. -
handlers: Здесь располагаются файлы YAML, содержащие определения обработчиков. Обработчики используются для выполнения действий в ответ на определенные события, например, перезапуск сервисов после изменения конфигурации. -
meta: Папка, содержащая файл YAML с метаданными о роли. Метаданные включают автора, зависимости, лицензию и другую информацию о роли. -
tasks: В этой папке находятся файлы YAML, определяющие задачи, которые должна выполнить роль. Здесь содержатся инструкции по управлению конфигурацией системы. -
templates: Папка, содержащая шаблоны файлов, которые могут быть обработаны Jinja2 для динамической генерации конфигурационных файлов или других текстовых файлов. -
tests: В этой папке могут располагаться файлы для тестирования роли, такие как инвентарные файлы для запуска тестов и сценарии тестирования. -
vars: Здесь хранятся файлы YAML, содержащие объявления переменных, используемых в роли. Эти переменные могут быть использованы в задачах и шаблонах. -
README.md: Файл с описанием роли, ее назначением, используемыми переменными и примерами использования.
Перейдите в директорию проекта и инициализируйте в нем репозиторий и при каждом шаге модификации, делайте коммит.
Начнем с заполнения самого простого для понимания пункта, это метаданные, там мы описываем роль, указываем теги и указываем зависимости если такие существует, он находится на пути meta/main.yml:
galaxy_info:
author: student
description: A simple role for ansible learning
company: ITT Department
license: BSD-3-Clause
min_ansible_version: "2.1"
galaxy_tags: []
dependencies: []
В нашем курсе мы не рассматриваем тестирование ролей, поэтому удалим папку tests
rm -rf tests
Перенесем существующий плейбук в tasks/main.yml приводя его к виду:
---
# tasks file for itt_labs
- name: Install and configure nginx
hosts: node
become: true
tasks:
block:
- name: Install nginx "Debian"
ansible.builtin.apt:
package:
- nginx
state: present
update_cache: true
when: ansible_facts['os_family'] == "Debian"
- name: Install nginx "redhat"
ansible.builtin.yum:
name:
- nginx
state: present
when: ansible_facts['os_family'] == "RedHat"
- name: Copy config nginx
ansible.builtin.template:
src: nginx.conf
dest: /etc/nginx/nginx.conf
owner: root
group: root
mode: '0644'
Создадим файл nginx.conf.j2 в директории templates:
user {{ nginx_user }};
worker_processes 2048;
worker_priority -1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections {{worker_connections}};
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
reset_timedout_connection on;
client_body_timeout 35;
send_timeout 30;
gzip on;
gzip_min_length {{gzip_min_length}};
gzip_vary on;
gzip_proxied expired no-cache no-store private auth;
gzip_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript application/javascript; gzip_disable "msie6";
types_hash_max_size 2048;
client_max_body_size {{client_max_body_size}};
proxy_buffer_size 64k;
proxy_buffers 4 64k;
proxy_busy_buffers_size 64k;
server_names_hash_bucket_size 64;
include /etc/nginx/conf.d/*.conf;
include /etc/nginx/sites-enabled/*;
}
Количество переменных изменилось, и теперь нам можно добавить новые переменные для роли, они будут находится по пути vars/main.yml
---
# vars file for itt_labs
worker_connections: 512
gzip_min_length: 1000
client_max_body_size: 512m
Также необходимо создать хендлеры которые будут работать с сервисом во время изменения его конфигураций, так создадим два хендлера для перезапуска и добавление в автозапуск демона(handlers/main.yml):
---
# handlers file for itt_labs
- name: Enable nginx service
ansible.builtin.systemd_service:
name: nginx.service
state: restarted
enabled: true
- name: Reload nginx service
ansible.builtin.systemd_service:
name: nginx.service
state: restarted
И для того, чтобы эти хендлеры вызывались, нам необходимо явно прописать у задач notify после которых будет необходимо перезапускать или добавлять в автозапуск nginx, так общий файл с задачами примет вид:
---
# tasks file for itt_labs
- name: Install and configure nginx
hosts: node
become: true
tasks:
block:
- name: Install nginx "Debian"
ansible.builtin.apt:
package:
- nginx
state: present
update_cache: true
when: ansible_facts['os_family'] == "Debian"
notify: Enable nginx service
- name: Install nginx "redhat"
ansible.builtin.yum:
name:
- nginx
state: present
when: ansible_facts['os_family'] == "RedHat"
notify: Enable nginx service
- name: Copy config nginx
ansible.builtin.template:
src: nginx.conf
dest: /etc/nginx/nginx.conf
owner: root
group: root
mode: '0644'
notify: Reload nginx service
Задание для самостоятельного выполнения
- Напишите роль для автоматизации развертывания проекта
- Создайте репозиторий и закоммитьте роль
Автоматизация сборки и развертывания приложений. Gitlab CI.
0. Схема стенда

1. Подготовка репозитория
Сделайте форк репозитория: https://gitlab.resds.ru/itt/sample-project
2. Подготовка раннера
- Перейдите в настройки проекта
- Перейдите в настройки CI/CD

- Разверните пункт отвечающий за раннеры и нажмите
New project runner
- Введите данные для раннера и добавьте теггов которые будут как-то обозначать общие признаки раннеров

- Нажмите
Create Runner - Перейдите на узел в котором должен будет работать раннер и установите его
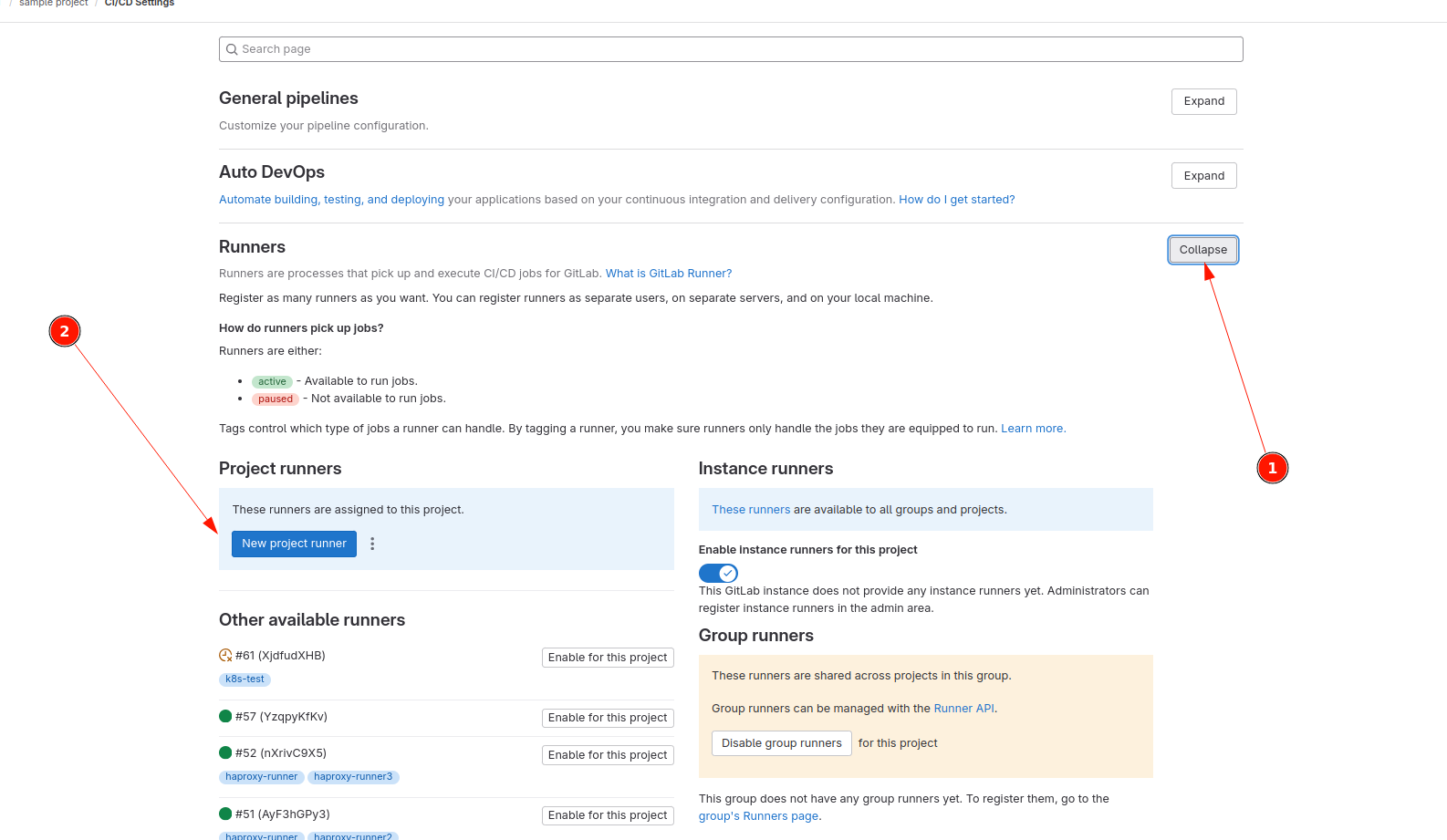
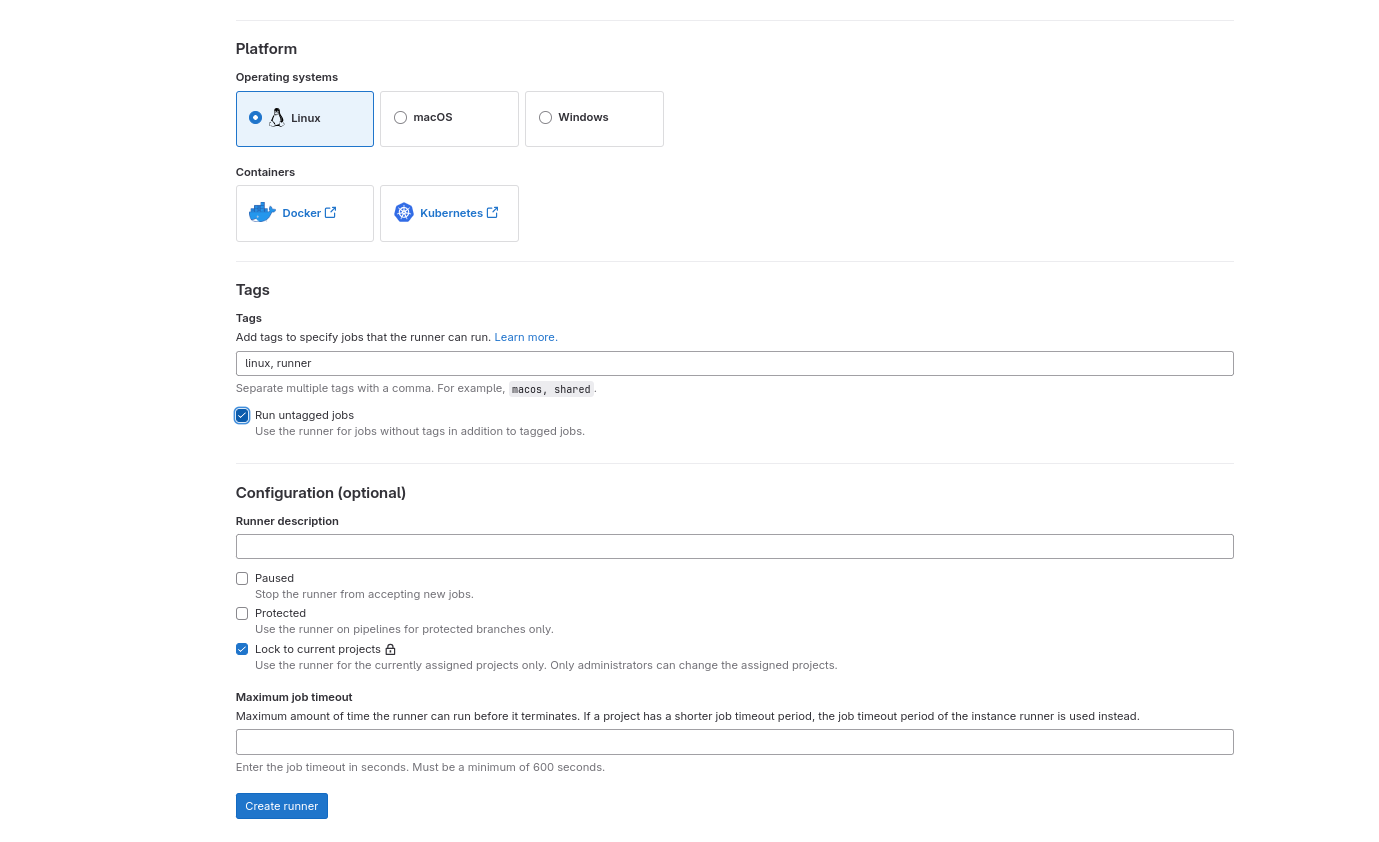
sudo curl -L --output /usr/local/bin/gitlab-runner https://gitlab-runner-downloads.s3.amazonaws.com/latest/binaries/gitlab-runner-linux-amd64
sudo chmod +x /usr/local/bin/gitlab-runner
sudo useradd --comment 'GitLab Runner' --create-home gitlab-runner --shell /bin/bash
sudo gitlab-runner install --user=gitlab-runner --working-directory=/home/gitlab-runner
- Установите на узле раннера Docker
- Зарегистрируйте раннер

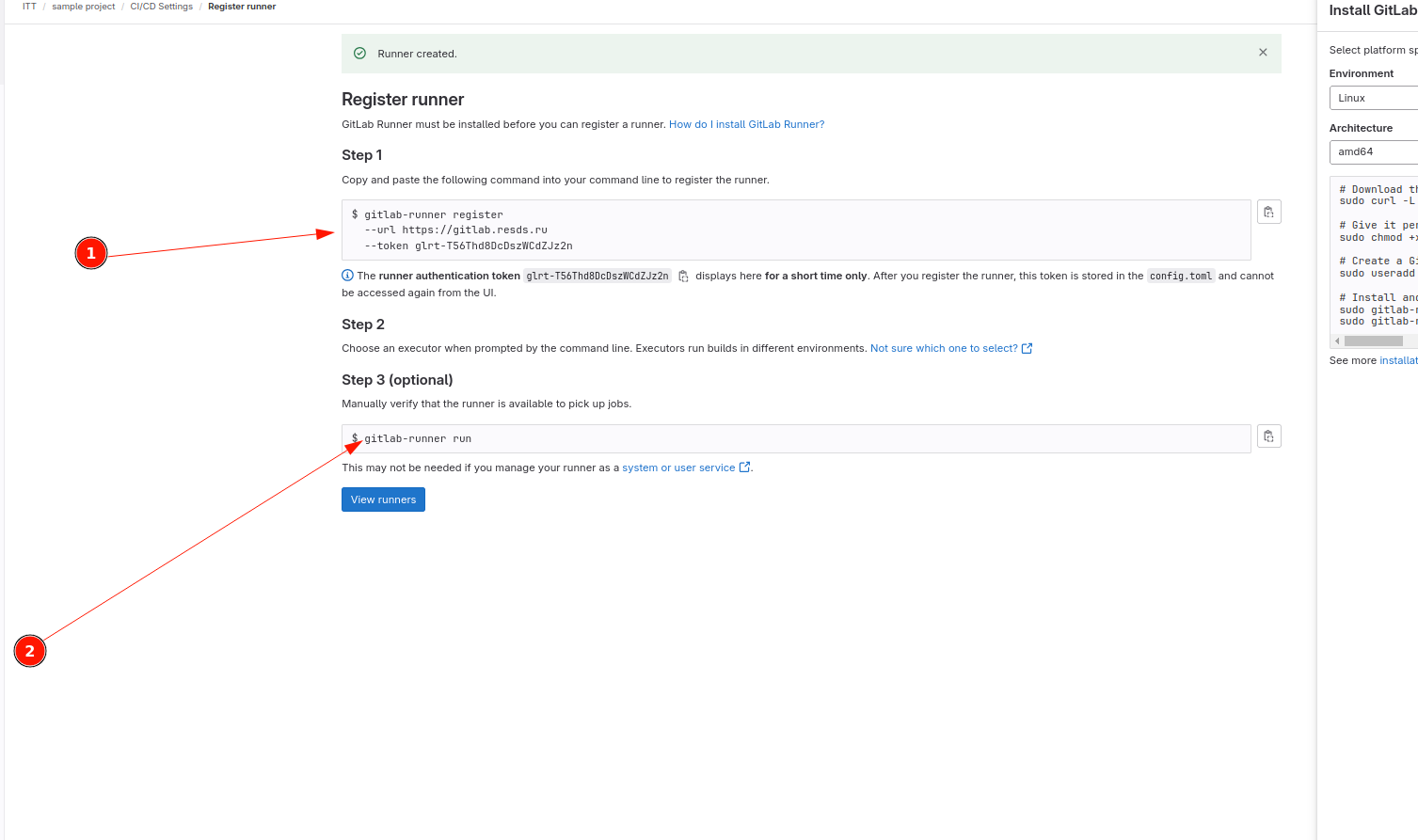
Задание
- Создайте новую ветку
feature/ci-cd - В новой ветке создайте многоуровневый
.gitlab-ci.yml- Статическое тестирования кода(прогнать линтерами код)
- Сборка контейнеров и отправка в gitlab-registry
- Запуск собранного приложения с использованием ранее загруженного образа
- Добавьте еще один раннер
- Добавьте деплой на еще один сервер
- С помощью тегов сделайте деплой на 2 узла при запуске
- Повторяющийся код уберите с помощью
Anchors - Установите зависимости между запускаемыми шагами
- Разделите запуск между узлами
- Разделите 2 узла по ролям:
-
dev -
prod
-
- Запуск на
prodосуществляется вручную после успешного наdev
- Разделите 2 узла по ролям:
- Смерджите ветку в
main
Автоматизация развертывания приложений. Kubernetes.
Схема стенда

Подготовка окружения
-
Загрузите версию
v1.25.9с помощью команды:curl -LO https://dl.k8s.io/release/v1.25.9/bin/linux/amd64/kubectl -
Сделайте бинарный файл kubectl исполняемым:
chmod +x ./kubectl -
Переместите бинарный файл в директорию из переменной окружения PATH:
sudo mv ./kubectl /usr/local/bin/kubectl -
Убедитесь, что установлена последняя версия:
kubectl version --client
-
Установите CLI для OpenStack:
sudo pip install cryptography==3.3.2 sudo pip install python-openstackclient sudo pip install python-cinderclient python-magnumclient python-octaviaclient -
Загрузите учетные данные, для получения доступа к API. Для этого необходимо авторизоваться на
cloud.resds.ruв правом верхнем углу нажмите на клавишу "Загрузите файл OpenStack RC" и выберете в выпадающем меню "OpenStack RC-файл" и переместите этот файл в локальную директорию пользователя с названием "openstack-client.sh" -
Добавьте в переменные среды полученные данные из прошлого шага:
source ~/openstack-client.shПри добавлении переменных среды, будет запрошен пароль, и добавлен в переменные среды на время сессии
-
Для проверки работоспособности клиента можно попробовать получить список вычислительных узлов в проекте
openstack server listТакже можно увидеть список кластер k8s
openstack coe cluster list -
Также добавим автодополнение для bash:
echo 'source <(kubectl completion bash)' >>~/.bashrc source ~/.bashrc

Создание кластера
- Авторизуйтесь
cloud.resds.ru - Перейдите в
Проект->Container Infra->Clusters - Нажмите
Create Cluster - Задайте название кластера в поле
Cluster Name, название кластераTraining-cluster-{Фамилия}, как примерTraining-cluster-Tarabanov - В
Cluster Templateвыберите пунктc39-kube-1.25-oct-ing - Зона доступности кластера
nova - Выберите ключевую пару
- Как размер кластера выберете 1 мастер узел и 2 рабочих узла
- Нажмите отправить
- После отправки необходимо дождаться создания кластера, это может занять некоторое время. Кластер можно считать созданным после смены статуса на
CREATE_COMPLETEиHealth StatusвHEALTHY
Работа с кластером
-
Перейдите на предварительно настроенный узел
-
Добавьте переменные среды
-
Получите конфигурационный файл для подключения к кластеру с помощью CLI
openstack coe cluster config {Название кластера созданного вами}
export KUBECONFIG=/home/cloudadmin/config -
Проверьте работу kubectl
kubectl get nodes
-
Создания ингреса для нашего приложения:
Ингрес будет использовать облачный балансировщик Octavia, который реализуют балансировщик на базе облачной платформы OpenStack. Для начала необходимо посмотреть существующие балансировщики в облачной платформе с помощью команды:
openstack loadbalancer listСоздадим файл с конфигурацией ингреса ingress.yaml
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: annotations: kubernetes.io/ingress.class: openstack octavia.ingress.kubernetes.io/internal: "false" name: octavia-ingress spec: rules: - host: test.com http: paths: - backend: service: name: sample-front port: number: 80 path: / pathType: PrefixДанный фрагмент конфигурации определяет параметры создаваемого ингресса в Kubernetes. Этот конфиг определяет следующие основные параметры:
- apiVersion: Версия API, используемая для определения структуры конфигурации.
- kind: Тип объекта, в данном случае, это ингресс.
- metadata: Метаданные объекта, такие как имя и пространство имен.
- annotations: Аннотации предоставляют дополнительные метаданные об ингрессе.
- spec: Определяет спецификацию правил ингресса, включая хосты и пути, а также их бекенды.
Для данного ингресса мы определили, что будет использоваться домен test.com и для него будет использоваться бекенд сервисом
sample-frontи посылать запросы на 80 порт сервиса, переход будет осуществляться при любом запросе к доменуhttp://test.com/. Чтобы применить выполненную команду, необходимо ввести команду:


kubectl apply -f ingress.yaml
После выполнения данной команды начнется создание балансировщика в платформе OpenStack, чтобы отследить создание балансировщика можно выполнять команду:
openstack loadbalancer list
Если после создания балансировщика появилась ошибка в столбце provisioning_status у вашего балансировщика, выполните команду:
openstack loadbalancer failover <loadbalancer id>
Если все еще находится в состоянии ошибки и не выходит после этой команды, пишите @tarabanov
Пока балансировщик никуда не обращается, давайте создадим поды и сервисы для нашего веб приложения.
Для этого начнем создание конфигурационного файла для фронтенда приложения, для этого начнем с создания файла sample-web-deployments.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-front
labels:
app: sample-front
spec:
selector:
matchLabels:
app: sample-front
template:
metadata:
labels:
app: sample-front
spec:
containers:
- name: sample-front
image: registry.gitlab.resds.ru/itt/sample-project:front
ports:
- containerPort: 3000
Этот фрагмент конфигурации представляет собой определение деплоймента в Kubernetes, который управляет подами для запуска и масштабирования приложения. Давайте разберем его по шагам:
- apiVersion: apps/v1 и kind: Deployment: Эти строки определяют, что мы создаем деплоймент в Kubernetes API версии 1 для управления подами.
- metadata: В этом разделе определяется метаданные деплоймента, такие, как его имя и метки (labels), которые могут использоваться для идентификации и поиска этого ресурса в Kubernetes кластере.
- spec: Этот раздел определяет спецификацию деплоймента, включая:
- selector: Определяет, какие поды должны быть управляемы деплойментом. В данном случае, деплоймент будет управлять подами, которые имеют метку
app: sample-front - template: Определяет шаблон для создания новых подов. Внутри template указываются метаданные и спецификация контейнера.
- metadata.labels: Это метки, которые будут присвоены создаваемым подам. В данном случае, создаваемые поды будут иметь метку app: sample-front, что соответствует селектору деплоймента.
-
spec.containers: Определяет контейнеры, которые будут запущены в подах. В данном случае, определен только один контейнер:-
name: sample-front: Это имя контейнера. -
image: registry.gitlab.resds.ru/itt/sample-project:front: Это образ контейнера, который будет загружен и запущен в поде. -
ports: Это список портов, которые контейнер будет прослушивать. В данном случае, контейнер будет прослушивать порт3000внутри себя, что означает, что приложение в контейнере будет доступно по этому порту внутри кластера Kubernetes.
-
- selector: Определяет, какие поды должны быть управляемы деплойментом. В данном случае, деплоймент будет управлять подами, которые имеют метку
Теперь создадим сервис для фронтенда sample-web-deployments.yaml
kind: Service
apiVersion: v1
metadata:
name: sample-front
labels:
app: sample-front
spec:
ports:
- port: 3000
targetPort: 3000
selector:
app: sample-front
type: NodePort
Можно заметить, что использовался порт 3000 для работы сервиса, а в ингрес контроллере указывали 80 при его создании, отредактируем ингресс для доступа через 3000 порт.
kubectl edit ing/octavia-ingress
В нем необходимо изменить:
port:
number: 80
На
port:
number: 3000
Проверьте фронтед, для этого необходимо проверим какой ip адрес получил ingress, для этого введите команду:
kubectl get ing
В столбце ADDRESS будет указан внешний адрес балансировщика.
Откройте в браузере фронтенд и убедитесь, что он запустился и работает.
Стоит заметить, что ответ будет происходить только при запросе по доменному имени. Стоит обеспечить доступность домен по DNS или добавить в файл hosts вашей операционной системы.
После удачной проверки работы фронтенда приступим к добавлению бекенда. back-service-pods.yaml:
---
kind: Service
apiVersion: v1
metadata:
name: sample-back
labels:
app: sample-back
spec:
ports:
- port: 5000
targetPort: 5000
selector:
app: sample-back
type: NodePort
back-pods.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-back
labels:
app: sample-back
spec:
replicas: 2
selector:
matchLabels:
app: sample-back
template:
metadata:
labels:
app: sample-back
spec:
containers:
- name: sample-back
image: registry.gitlab.resds.ru/itt/sample-project:back
ports:
- containerPort: 5000
Также необходимо отредактировать ingress, в этот раз мы сделаем это с помощью редактирования конфигурационного файла(ingress.yaml):
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: openstack
octavia.ingress.kubernetes.io/internal: "false"
name: test-octavia-ingress
namespace: default
spec:
rules:
- host: test.com
http:
paths:
- backend:
service:
name: sample-back
port:
number: 5000
path: /api
pathType: Prefix
- backend:
service:
name: sample-back
port:
number: 5000
path: /api/notes
pathType: Prefix
- backend:
service:
name: sample-front
port:
number: 3000
path: /
pathType: Prefix
и применим изменившеюся конфигурацию:
kubectl apply -f ingress.yaml
Проверьте работу веб приложения.